Alătură-te evenimentului în care liderii companiilor au încredere de aproape două decenii. VB Transform reunește oamenii care construiesc o strategie reală de inteligență artificială pentru companii. Află mai multe
Un nou cadru de la cercetătorii de la Universitatea din Illinois, Urbana-Champaignși Universitatea din California, Berkeley oferă dezvoltatorilor mai mult control asupra modului în care „gândesc” modelele lingvistice mari (LLM), îmbunătățindu-le capacitățile de raționament și utilizând în același timp mai eficient bugetul lor de inferență.
Cadrul, numit AlphaOne (α1), este un scalarea timpului de testare tehnică, care modifică comportamentul unui model în timpul inferenței fără a fi nevoie de re-antrenament costisitor. Aceasta oferă o metodă universală pentru modularea procesului de raționament al LLM-urilor avansate, oferind dezvoltatorilor flexibilitatea de a îmbunătăți performanța în sarcini complexe într-un mod mai controlat și mai rentabil decât abordările existente.
Provocarea gândirii lente
În ultimii ani, dezvoltatorii de modele de raționament extinse (LRM), cum ar fi OpenAI o3 şi DeepSeek-R1, au încorporat mecanisme inspirate de Gândirea „Sistemului 2”—modul lent, deliberat și logic al cunoașterii umane. Acesta este distinct de gândirea „Sistemului 1”, care este rapidă, intuitivă și automată. Incorporarea capabilităților Sistemului 2 permite modelelor să rezolve probleme complexe în domenii precum matematica, codarea și analiza datelor.
Modelele sunt antrenate să genereze automat indicii de tranziție precum „așteptați”, „hmm” sau „alternativ” pentru a declanșa gândirea lentă. Când apare unul dintre aceste indicii, modelul se oprește pentru a se auto-reflecta asupra pașilor anteriori și pentru a-și corecta cursul, la fel cum o persoană se oprește pentru a regândi o problemă dificilă.
Totuși, modelele de raționament nu își folosesc întotdeauna eficient capacitățile de gândire lentă. Diferite studii arată că sunt predispuse fie la „gândirea excesivă” a problemelor simple, la risipa resurselor de calcul, fie la „gândirea insuficientă” a celor complexe, ceea ce duce la răspunsuri incorecte.
Pe măsură ce Lucrare AlphaOne notează: „Acest lucru se datorează incapacității LRM-urilor de a găsi tranziția optimă de raționament de tip sistem 1-la-2, similară cu cea umană, și capacităților limitate de raționament, ceea ce duce la performanțe nesatisfăcătoare ale raționamentului.”
Există două metode comune pentru a aborda această problemă. Scalarea paralelă, precum abordarea „cel mai bun din N”, rulează un model de mai multe ori și alege cel mai bun răspuns, ceea ce este costisitor din punct de vedere computațional. Scalarea secvențială încearcă să moduleze procesul de gândire în timpul unei singure rulări. De exemplu, s1 este o tehnică ce forțează o gândire mai lentă prin adăugarea de jetoane de „așteptare” în contextul modelului, în timp ce „Lanțul de proiectare„Metoda CoD” (CoD) determină modelul să folosească mai puține cuvinte, reducându-i astfel bugetul de gândire. Aceste metode, însă, oferă soluții rigide, universale, care sunt adesea ineficiente.”
Un cadru universal pentru raționament
În loc să crească sau să reducă pur și simplu bugetul de gândire, cercetătorii din spatele AlphaOne au pus o întrebare mai fundamentală: este posibil să se dezvolte o strategie mai bună pentru tranziția între gândirea lentă și cea rapidă, care să poată modula bugetele de raționament în mod universal?
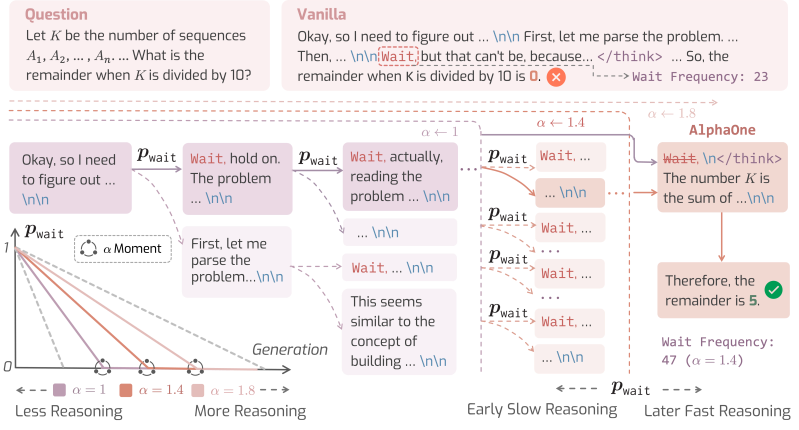
Framework-ul lor, AlphaOne, oferă dezvoltatorilor un control detaliat asupra procesului de raționament al modelului în momentul testării. Sistemul funcționează prin introducerea parametrului Alpha (α), care acționează ca un controler pentru scalarea bugetului fazei de gândire a modelului.
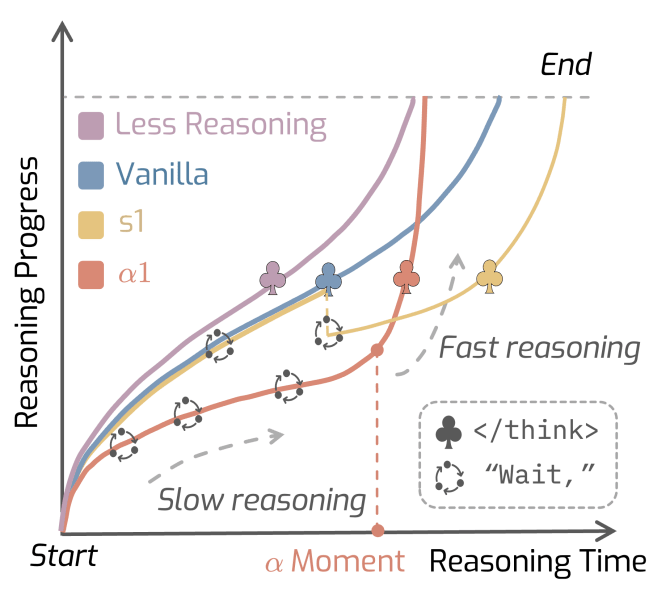
Înainte de un anumit punct al generației, pe care cercetătorii îl numesc „momentul α”, AlphaOne programează strategic frecvența cu care introduce un token de „așteptare” pentru a încuraja gândirea lentă și deliberată. Acest lucru permite ceea ce lucrarea descrie ca „gândire atât controlabilă, cât și scalabilă”.
Odată ce „momentul α” este atins, framework-ul introduce un token în contextul modului, punând capăt procesului lent de gândire și forțând modelul să treacă la raționament rapid și să producă răspunsul final.
Tehnicile anterioare aplică de obicei ceea ce cercetătorii numesc „modulație dispersă”, făcând doar câteva ajustări izolate, cum ar fi adăugarea unui token de „așteptare” o dată sau de două ori pe parcursul întregului proces. AlphaOne, în schimb, poate fi configurat să intervină des (dens) sau rar (dispers), oferind dezvoltatorilor un control mai granular decât alte metode.
„Considerăm AlphaOne ca o interfață unificată pentru raționamentul deliberat, complementară stimulării bazate pe lanțuri de gânduri sau ajustării bazate pe preferințe și capabilă să evolueze alături de arhitecturile modelelor”, a declarat echipa AlphaOne pentru VentureBeat în comentariile scrise. „Concluzia cheie nu este legată de detaliile implementării, ci de principiul general: modularea structurată, de la lent la rapid, a procesului de raționament sporește capacitatea și eficiența.”
AlphaOne în acțiune
Cercetătorii au testat AlphaOne pe trei modele diferite de raționament, cu dimensiuni ale parametrilor cuprinse între 1,5 miliarde și 32 de miliarde. Ei au evaluat performanța sa în șase teste de referință dificile în matematică, generare de cod și rezolvarea problemelor științifice.
Ei au comparat AlphaOne cu trei modele de referință: modelul standard, nemodificat; metoda s1, care crește monotonic gândirea lentă; și metoda Lanțului de schițe (CoD), care o reduce monotonic.
Rezultatele au produs câteva constatări cheie care sunt deosebit de relevante pentru dezvoltatorii care construiesc aplicații de inteligență artificială.
În primul rând, o strategie de tip „gândire lentă mai întâi, apoi gândire rapidă” duce la o performanță mai bună a raționamentului în modelele de gândire lentă (LRM). Acest lucru evidențiază o discrepanță fundamentală între modelele de gândire lentă (LLM) și cogniția umană, care este de obicei structurată pe baza gândirii rapide urmate de gândirea lentă. Spre deosebire de oameni, cercetătorii au descoperit că modelele beneficiază de gândirea lentă impusă înainte de a acționa rapid.
„Acest lucru sugerează că raționamentul eficient bazat pe inteligență artificială nu rezultă din imitarea experților umani, ci din modularea explicită a dinamicii raționamentului, ceea ce se aliniază cu practici precum ingineria promptă și inferența etapizată deja utilizate în aplicațiile din lumea reală”, a declarat echipa AlphaOne. „Pentru dezvoltatori, aceasta înseamnă că proiectarea sistemului ar trebui să impună în mod activ un program de raționament de la lent la rapid pentru a îmbunătăți performanța și fiabilitatea, cel puțin deocamdată, în timp ce raționamentul model rămâne imperfect.”
O altă descoperire interesantă a fost că investiția în gândirea lentă poate duce la o inferență generală mai eficientă. „În timp ce gândirea lentă încetinește raționamentul, lungimea totală a token-ului este redusă semnificativ cu α1, inducând un progres al raționamentului mai informativ adus de gândirea lentă”, se arată în lucrare. Aceasta înseamnă că, deși modelul necesită mai mult timp pentru a „gândi”, produce o cale de raționament mai concisă și mai precisă, reducând în cele din urmă numărul total de token-uri generate și scăzând costurile inferenței.
Comparativ cu standardele de referință s1, AlphaOne reduce utilizarea medie a tokenurilor cu ~21%, rezultând o suprasarcină de calcul mai mică, sporind în același timp acuratețea raționamentului cu 6,15%, chiar și în problemele de matematică, științe și cod de nivel doctoral.
„Pentru aplicațiile enterprise, cum ar fi răspunsurile la interogări complexe sau generarea de cod, aceste câștiguri se traduc într-un beneficiu dublu: o calitate îmbunătățită a generării și economii semnificative de costuri”, a declarat AlphaOne. „Acestea pot duce la costuri mai mici ale inferenței, îmbunătățind în același timp ratele de succes ale sarcinilor și satisfacția utilizatorilor.”
În cele din urmă, studiul a constatat că inserarea de token-uri „așteptare” cu frecvență ridicată este utilă, AlphaOne obținând rezultate mai bune prin adăugarea token-ului semnificativ mai des decât metodele anterioare.
Oferind dezvoltatorilor un nou nivel de control, framework-ul AlphaOne, al cărui cod este așteptat să fie lansat în curând, i-ar putea ajuta să construiască aplicații mai stabile, fiabile și eficiente, bazate pe următoarea generație de modele de raționament.
„Pentru companiile care utilizează modele open-source sau personalizate, în special cele antrenate cu token-uri de tranziție în faza de pre-antrenament, AlphaOne este conceput pentru a fi ușor de integrat”, a declarat echipa AlphaOne pentru VentureBeat. „În practică, integrarea necesită de obicei modificări minime, cum ar fi simpla actualizare a numelui modelului în scripturile de configurare.”
