Doriți informații mai inteligente în căsuța dvs. poștală? Abonați-vă la newsletter-ele noastre săptămânale pentru a primi doar informații importante pentru liderii din domeniul inteligenței artificiale, datelor și securității în cadrul companiilor. Abonează-te acum
A trecut puțin peste o lună de când startup-ul chinez de inteligență artificială DeepSeek, o filială a High-Flyer Capital Management, cu sediul în Hong Kong, a lansat... cea mai recentă versiune a modelului său open source de succes DeepSeek, R1-0528.
La fel ca predecesorul său, DeepSeek-R1 — care a zguduit comunitățile de inteligență artificială și de afaceri globale cu cât de ieftin a fost antrenat și cât de bine a performat în sarcinile de raționament, toate disponibile gratuit dezvoltatorilor și întreprinderilor - R1-0528 este deja adaptat și remixat de alte laboratoare și dezvoltatori de inteligență artificială, în mare parte datorită licenței sale permisive Apache 2.0.
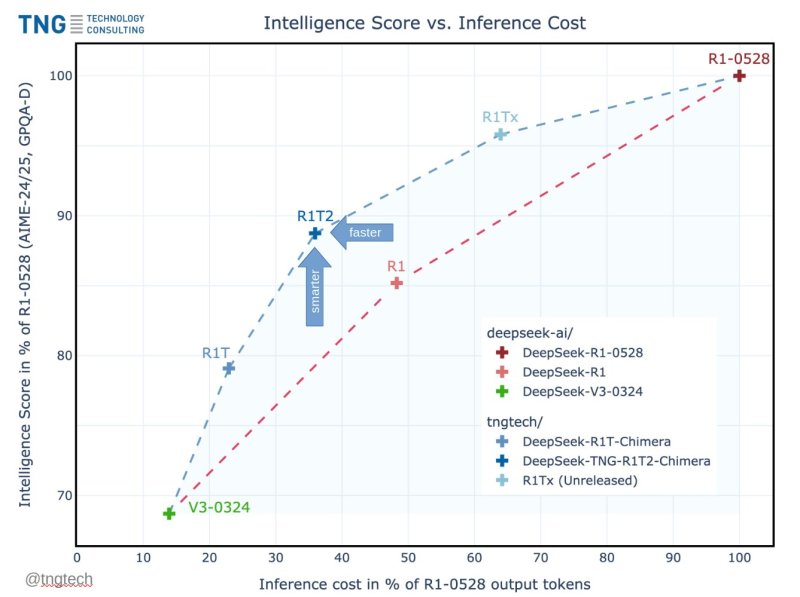
Săptămâna aceasta, firma germană, cu o vechime de 24 de ani... TNG Technology Consulting GmbH a lansat unul o astfel de adaptare: DeepSeek-TNG R1T2 Himera, cel mai recent model din familia Chimera de modele lingvistice mari (LLM). R1T2 oferă o creștere notabilă a eficienței și vitezei, atingând peste 90% din scorurile de referință ale inteligenței R1-0528, în timp ce generează răspunsuri cu mai puțin de 40% din numărul de token-uri de ieșire ale R1-0528.
Asta înseamnă că produce răspunsuri mai scurte, traducându-se direct în inferență mai rapidă și costuri de calcul mai miciPe placa de bază lansată de TNG pentru noul său R1T2 în comunitatea de partajare a codului de inteligență artificială Hugging Face, compania declară că este „cu aproximativ 20% mai rapid decât R1-ul obișnuit” (cel lansat în ianuarie) „și de peste două ori mai rapid decât R1-0528” (actualizarea oficială din mai de la DeepSeek).
Deja, reacția comunității dezvoltatorilor de inteligență artificială a fost incredibil de pozitivă. „LA NAIBA! DeepSeek R1T2 – 200% mai rapid decât R1-0528 și 20% mai rapid decât R1”, a scris Vaibhav (VB) Srivastav, lider senior la Hugging Face. pe X„Semnificativ mai bun decât R1 pe GPQA și AIME 24, realizat prin Assembly of Experts cu DS V3, R1 și R1-0528 — și este licențiat MIT, disponibil pe Hugging Face.”
Acest câștig este posibil datorită metodei Assembly-of-Experts (AoE) a TNG - o tehnică de construire a LLM-urilor prin fuzionarea selectivă a tensorilor de ponderare (parametri interni) din mai multe modele pre-antrenate pe care TNG le-a descris într-un lucrare publicată în mai pe arXiv, revista online cu acces deschis, fără evaluare inter pares.
Un succesor al modelului original R1T Chimera, R1T2 introduce o nouă configurație „Tri-Mind” care integrează trei modele părinte: DeepSeek-R1-0528, DeepSeek-R1 și DeepSeek-V3-0324. Rezultatul este un model conceput pentru a menține o capacitate ridicată de raționament, reducând în același timp semnificativ costul inferenței.
R1T2 este construit fără alte ajustări fine sau recalificare. Moștenește puterea de raționament a lui R1-0528, modelele de gândire structurate ale lui R1 și comportamentul concis, orientat spre instrucțiuni, al lui V3-0324 — oferind un model mai eficient, dar capabil, pentru utilizare în întreprinderi și cercetare.
Cum diferă Adunarea de Experți (AoE) de Amestec de Experți (MoE)
Amestec de experți (MoE) este un design arhitectural în care diferite componente, sau „experți”, sunt activate condiționat per intrare. În straturile de expertiză MoE, cum ar fi DeepSeek-V3 sau Mixtral, doar un subset al straturilor expert ale modelului (de exemplu, 8 din 256) sunt active în timpul transmiterii înainte a oricărui token dat. Acest lucru permite modelelor foarte mari să obțină un număr mai mare de parametri și o specializare mai mare, menținând în același timp costurile inferenței gestionabile - deoarece doar o fracțiune din rețea este evaluată per token.
Asamblarea experților (AoE) este o tehnică de îmbinare a modelelor, nu o arhitectură. Este utilizată pentru a crea un model nou din mai multe modele MoE pre-antrenate prin interpolarea selectivă a tensorilor lor de ponderare.
„Experții” din AoE se referă la componentele modelului care sunt îmbinate - de obicei tensorii experți rutați în straturile MoE - nu la experți activați dinamic la momentul execuției.
Implementarea AoE de către TNG se concentrează în principal pe fuzionarea tensorilor experți rutați - partea unui model cea mai responsabilă pentru raționamentul specializat - păstrând adesea straturile partajate și de atenție mai eficiente din modele mai rapide, cum ar fi V3-0324. Această abordare permite modelelor Chimera rezultate să moștenească puterea raționamentului fără a replica verbositatea sau latența celor mai puternice modele părinte.
Performanță și viteză: Ce arată de fapt testele de performanță
Conform comparațiilor de referință prezentate de TNG, R1T2 obține între 90% și 92% a performanței de raționament a celui mai inteligent sistem-părinte al său, DeepSeek-R1-0528, măsurată prin seturile de teste AIME-24, AIME-25 și GPQA-Diamond.

Totuși, spre deosebire de DeepSeek-R1-0528 — care tinde să producă răspunsuri lungi și detaliate datorită raționamentului său bazat pe lanțuri extinse de gânduri — R1T2 este conceput să fie mult mai concis. Oferă răspunsuri la fel de inteligente, folosind în același timp mult mai puține cuvinte.
În loc să se concentreze pe timpul brut de procesare sau pe numărul de token-uri pe secundă, TNG măsoară „viteza” în termeni de numărul de token-uri de ieșire per răspuns — o aproximare practică atât pentru cost, cât și pentru latență. Conform testelor de referință partajate de TNG, R1T2 generează răspunsuri folosind aproximativ 40% de token-uri cerut de R1-0528.
Asta se traduce printr-o Reducerea lungimii de ieșire 60%, ceea ce reduce direct timpul de inferență și sarcina de calcul, accelerând răspunsurile de 2X sau 200%.
Comparativ cu DeepSeek-R1 original, R1T2 este, de asemenea, în jur de... 20% mai concis în medie, oferind câștiguri semnificative în ceea ce privește eficiența pentru implementările cu randament ridicat sau sensibile la costuri.
Această eficiență nu vine în detrimentul inteligenței. După cum se arată în graficul de referință prezentat în lucrarea tehnică a TNG, R1T2 se situează într-o zonă dezirabilă pe curba inteligenței față de costul de ieșire. Păstrează calitatea raționamentului, minimizând în același timp verbozitatea - un rezultat esențial pentru aplicațiile enterprise unde viteza de inferență, debitul și costul contează.
Considerații privind implementarea și disponibilitatea
R1T2 este lansat sub o licență MIT permisivă și este disponibil acum pe Hugging Face, ceea ce înseamnă că este open source și disponibil pentru a fi utilizat și integrat în aplicații comerciale.
TNG notează că, deși modelul este potrivit pentru sarcini generale de raționament, nu este recomandat în prezent pentru cazuri de utilizare care necesită apelarea funcțiilor sau utilizarea instrumentelor, din cauza limitărilor moștenite de la linia sa DeepSeek-R1. Acestea ar putea fi abordate în actualizările viitoare.
Compania recomandă, de asemenea, utilizatorilor europeni să evalueze conformitatea cu Legea UE privind inteligența artificială, care intră în vigoare la 2 august 2025.
Întreprinderile care operează în UE ar trebui să revizuiască prevederile relevante sau să ia în considerare oprirea utilizării modelului după această dată, dacă cerințele nu pot fi îndeplinite.
Cu toate acestea, companiile americane care operează pe plan intern și deservesc utilizatori din SUA sau din alte națiuni sunt nu sub rezerva termenilor Legii UE privind inteligența artificială, ceea ce ar trebui să le ofere o flexibilitate considerabilă în utilizarea și implementarea acestui model de raționament gratuit, rapid și open source. Dacă oferă servicii utilizatorilor din UE, unii prevederile Legii UE se vor aplica în continuare.
TNG a pus deja la dispoziție variante anterioare de Chimera prin intermediul unor platforme precum OpenRouter și Chutes, unde se pare că procesau miliarde de token-uri zilnic. Lansarea R1T2 reprezintă o evoluție suplimentară în acest efort de disponibilitate publică.
Despre TNG Technology Consulting GmbH
Fondată în ianuarie 2001, TNG Technology Consulting GmbH are sediul în Bavaria, Germania, și are peste 900 de angajați, o concentrație mare de doctori și specialiști tehnici.
Compania se concentrează pe dezvoltarea de software, inteligență artificială și servicii DevOps/cloud, deservind clienți majori din industrii precum telecomunicații, asigurări, industria auto, comerț electronic și logistică.
TNG operează ca un parteneriat de consultanță bazat pe valori. Structura sa unică, bazată pe cercetare operațională și principii de autogestionare, susține o cultură a inovației tehnice.
Contribuie activ la comunitățile și cercetarea open-source, așa cum este demonstrat prin lansări publice precum R1T2 și publicarea metodologiei sale Assembly-of-Experts.
Ce înseamnă pentru factorii de decizie tehnică din cadrul întreprinderilor
Pentru directorii de tehnologie (CTO), proprietarii de platforme de inteligență artificială, liderii de inginerie și echipele de achiziții IT, R1T2 introduce beneficii tangibile și opțiuni strategice:
- Costuri de inferență mai miciCu mai puține jetoane de ieșire per sarcină, R1T2 reduce timpul și consumul de energie al GPU-ului, ceea ce se traduce direct în economii de infrastructură — lucru important în special în mediile cu randament ridicat sau în timp real.
- Calitate ridicată a raționamentului, fără costuri suplimentarePăstrează o mare parte din puterea de raționament a modelelor de top, precum R1-0528, dar fără a fi prea lungi. Este ideal pentru sarcini structurate (matematică, programare, logică) unde răspunsurile concise sunt preferabile.
- Deschis și modificabilLicența MIT permite controlul complet al implementării și personalizarea, permițând găzduirea privată, alinierea modelelor sau instruirea suplimentară în medii reglementate sau cu spații închise.
- Modularitate emergentăAbordarea AoE sugerează un viitor în care modelele sunt construite modular, permițând întreprinderilor să asambleze variante specializate prin recombinarea punctelor forte ale modelelor existente, în loc să se reantreneze de la zero.
- AvertismenteÎntreprinderile care se bazează pe apelarea funcțiilor, utilizarea instrumentelor sau orchestrarea avansată a agenților ar trebui să ia în considerare limitările actuale, deși actualizările viitoare Chimera ar putea remedia aceste lacune.
TNG încurajează cercetătorii, dezvoltatorii și utilizatorii din mediul de afaceri să exploreze modelul, să-i testeze comportamentul și să ofere feedback. R1T2 Chimera este disponibil la huggingface.co/tngtech/DeepSeek-TNG-R1T2-Chimera, iar întrebările tehnice pot fi adresate către research@tngtech.com.
Pentru informații tehnice și metodologia de referință, lucrarea de cercetare a TNG este disponibilă la arXiv:2506.14794.
