Alătură-te evenimentului în care liderii companiilor au încredere de aproape două decenii. VB Transform reunește oamenii care construiesc o strategie reală de inteligență artificială pentru companii. Află mai multe
Startup-ul chinezesc de inteligență artificială MiniMax, probabil cel mai bine cunoscut în Occident pentru succesul său realist Model video cu inteligență artificială Hailuo, a lansat cel mai recent model de limbaj extins, MiniMax-M1 — și o veste excelentă pentru companii și dezvoltatori, este complet sursă deschisă sub licența Apache 2.0, ceea ce înseamnă că firmele îl pot prelua și utiliza pentru aplicații comerciale și îl pot modifica după bunul plac, fără restricții sau plăți.
M1 este o ofertă open-weight care stabilește noi standarde în raționamentul în context lung, utilizarea instrumentelor agentice și performanța eficientă a calculului. Este disponibilă astăzi în comunitatea de partajare a codului AI. Față îmbrățișătoare şi Comunitatea rivală de partajare a codului Microsoft, GitHub, prima lansare a ceea ce compania a numit „MiniMaxWeek” de pe contul său de socializare de pe X — fiind așteptate și alte anunțuri de produse.
MiniMax-M1 se distinge printr-o fereastră de context de 1 milion de jetoane de intrare și până la 80.000 de jetoane de ieșire, poziționându-l ca unul dintre cele mai extinse modele disponibile pentru sarcini de raționament în context lung.
„Fereastra contextuală” din modelele lingvistice mari (LLM) se referă la numărul maxim de token-uri pe care modelul le poate procesa simultan - inclusiv atât datele de intrare, cât și cele de ieșire. Token-urile sunt unitățile de bază ale textului, care pot include cuvinte întregi, părți de cuvinte, semne de punctuație sau simboluri de cod. Aceste token-uri sunt convertite în vectori numerici pe care modelul îi folosește pentru a reprezenta și manipula sensul prin parametrii săi (pondere și erori). Ele sunt, în esență, limba nativă a LLM.
Pentru comparație, GPT-4o al OpenAI are o fereastră de context de doar 128.000 de tokenuri — suficiente pentru a fi schimbate despre informațiile conținute într-un roman între utilizator și model într-o singură interacțiune dus-întors. Cu 1 milion de token-uri, MiniMax-M1 putea schimba o mică sumă colectare sau informații despre o serie de cărți. Google Gemini 2.5 Pro oferă o limită superioară de 1 milion pentru contextul tokenurilor., de asemenea, cu o fereastră de 2 milioane în lucru.
Însă M1 are un alt as în mânecă: a fost antrenat folosind învățarea prin consolidare într-o tehnică inovatoare, ingenioasă și extrem de eficientă. Modelul este antrenat folosind o arhitectură hibridă Mixture-of-Experts (MoE) cu un mecanism de atenție rapidă conceput pentru a reduce costurile inferenței.
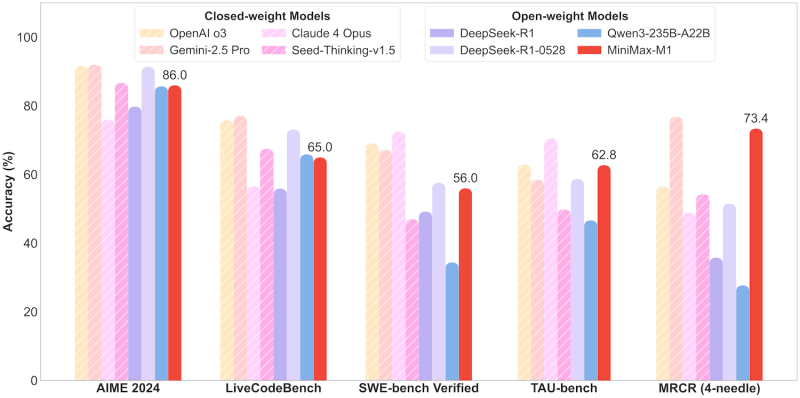
Conform raportului tehnic, MiniMax-M1 consumă doar 25% din operațiile în virgulă mobilă (FLOP) necesare de DeepSeek R1 la o lungime de generație de 100.000 de token-uri.
Arhitectură și variante
Modelul este disponibil în două variante — MiniMax-M1-40k și MiniMax-M1-80k — referindu-se la „bugetele lor de gândire” sau lungimile de ieșire.
Arhitectura este construită pe fundația anterioară MiniMax-Text-01 a companiei și include 456 de miliarde de parametri, cu 45,9 miliarde activate per token.
O caracteristică remarcabilă a lansării este costul de antrenament al modelului. MiniMax raportează că modelul M1 a fost antrenat folosind învățarea prin consolidare (RL) la scară largă, la o eficiență rar întâlnită în acest domeniu, cu un cost total de $534.700.
Această eficiență se datorează unui algoritm RL personalizat numit CISPO, care elimină ponderile de eșantionare a importanței în loc de actualizări de token-uri, și designului hibrid de atenție care ajută la eficientizarea scalării.
Aceasta este o sumă uimitor de „iefică” pentru un LLM de frontieră, deoarece DeepSeek și-a antrenat modelul de raționament R1 la un cost raportat de $5-$6 milioane, în timp ce costul de instruire al modelului GPT-4 de la OpenAIs — un model vechi de peste doi ani — a fost se spune că depășește $100 milioaneAcest cost provine atât din prețul unităților de procesare grafică (GPU), hardware-ul de calcul masiv paralel fabricat în principal de companii precum Nvidia, care poate costa între 20.000 și 30.000 de dolari sau mai mult per modul, cât și din energia necesară pentru a rula aceste cipuri în mod continuu în centre de date de mari dimensiuni.
Performanța de referință
MiniMax-M1 a fost evaluat pe baza unei serii de teste de performanță stabilite care testează raționamentul avansat, ingineria software și capacitățile de utilizare a instrumentelor.
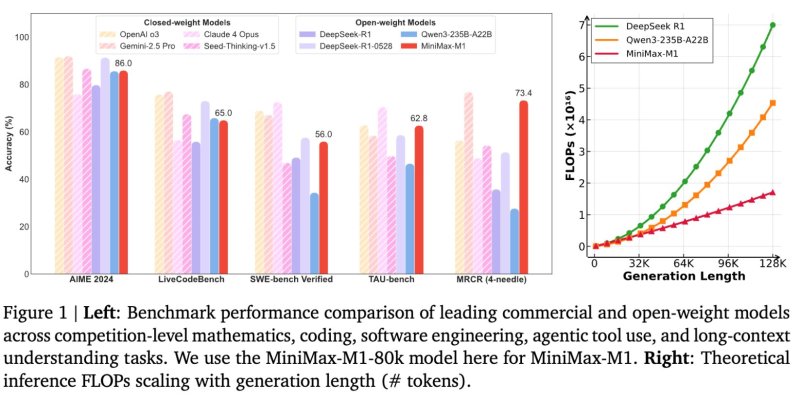
În cadrul testului AIME 2024, un test de performanță pentru o competiție de matematică, modelul M1-80k a obținut un scor de precizie de 86,0%. De asemenea, oferă performanțe puternice în codare și sarcini cu context lung, realizând:
- 65.0% pe LiveCodeBench
- 56.0% pe bancul SWE verificat
- 62.8% pe bancul TAU
- 73.4% pe OpenAI MRCR (versiunea cu 4 ace)
Aceste rezultate plasează MiniMax-M1 înaintea altor competitori cu greutate deschisă, cum ar fi DeepSeek-R1 și Qwen3-235B-A22B la mai multe sarcini complexe.
Deși modelele cu greutate închisă, precum o3 și Gemini 2.5 Pro de la OpenAI, încă depășesc unele teste de performanță, MiniMax-M1 reduce considerabil decalajul de performanță, rămânând în același timp accesibil gratuit sub o licență Apache-2.0.
Pentru implementare, MiniMax recomandă vLLM ca backend de servire, invocând optimizarea sa pentru sarcini de lucru mari pe modele, eficiența memoriei și gestionarea cererilor în lot. Compania oferă, de asemenea, opțiuni de implementare utilizând biblioteca Transformers.
MiniMax-M1 include capabilități de apelare structurată a funcțiilor și este echipat cu o API pentru chatbot, cu instrumente de căutare online, generare de videoclipuri și imagini, sinteză vocală și clonare vocală. Aceste caracteristici își propun să sprijine un comportament agentiv mai amplu în aplicațiile din lumea reală.
Implicații pentru factorii de decizie tehnică și cumpărătorii din mediul de afaceri
Accesul deschis, capacitățile de context lung și eficiența de calcul ale MiniMax-M1 abordează mai multe provocări recurente pentru profesioniștii tehnici responsabili de gestionarea sistemelor de inteligență artificială la scară largă.
Pentru inginerii responsabili de întregul ciclu de viață al LLM-urilor — cum ar fi optimizarea performanței modelului și implementarea în termene strânse — MiniMax-M1 oferă un profil de costuri operaționale mai mic, suportând în același timp sarcini avansate de raționament. Fereastra sa contextuală extinsă ar putea reduce semnificativ eforturile de preprocesare pentru documentele întreprinderii sau datele de jurnal care acoperă zeci sau sute de mii de token-uri.
Pentru cei care gestionează canale de orchestrare bazate pe inteligență artificială, capacitatea de a regla fin și implementa MiniMax-M1 folosind instrumente consacrate precum vLLM sau Transformers permite o integrare mai ușoară în infrastructura existentă. Arhitectura cu atenție hibridă poate ajuta la simplificarea strategiilor de scalare, iar performanța competitivă a modelului în ceea ce privește raționamentul în mai mulți pași și testele de inginerie software oferă o bază de capabilități ridicate pentru copiloți interni sau sisteme bazate pe agenți.
Din perspectiva unei platforme de date, echipele responsabile de menținerea unei infrastructuri eficiente și scalabile pot beneficia de suportul oferit de M1 pentru apelarea structurată a funcțiilor și de compatibilitatea sa cu pipeline-urile automate. Natura sa open-source permite echipelor să adapteze performanța la stiva lor, fără a fi dependente de un furnizor.
Responsabilii cu securitatea pot găsi, de asemenea, valoare în evaluarea potențialului M1 pentru implementarea securizată, locală, a unui model de înaltă capacitate, care nu se bazează pe transmiterea de date sensibile către endpoint-uri terțe.
Luate împreună, MiniMax-M1 oferă o opțiune flexibilă pentru organizațiile care doresc să experimenteze sau să extindă capabilitățile avansate de inteligență artificială, gestionând în același timp costurile, rămânând în limitele operaționale și evitând constrângerile de proprietate.
Lansarea semnalează concentrarea continuă a MiniMax pe modele de inteligență artificială practice și scalabile. Prin combinarea accesului deschis cu o arhitectură avansată și eficiență de calcul, MiniMax-M1 poate servi drept model fundamental pentru dezvoltatorii care construiesc aplicații de generație următoare ce necesită atât profunzime a raționamentului, cât și înțelegerea input-ului pe termen lung.
Vom urmări celelalte lansări MiniMax pe parcursul săptămânii. Rămâneți pe fază!
