Doriți informații mai inteligente în căsuța dvs. poștală? Abonați-vă la newsletter-ele noastre săptămânale pentru a primi doar informații importante pentru liderii din domeniul inteligenței artificiale, datelor și securității în cadrul companiilor. Abonează-te acum
Cercetătorii de la Laboratoarele Katanemo au introdus Arch-Router, un nou model și cadru de rutare conceput pentru a mapa inteligent interogările utilizatorilor la cel mai potrivit model de limbaj mare (LLM).
Pentru întreprinderile care dezvoltă produse care se bazează pe mai multe LLM-uri, Arch-Router își propune să rezolve o provocare cheie: cum să direcționeze interogările către cel mai bun model pentru job, fără a se baza pe o logică rigidă sau pe o reinstruire costisitoare de fiecare dată când ceva se schimbă.
Provocările rutării LLM
Pe măsură ce numărul de LLM-uri crește, dezvoltatorii trec de la configurații cu un singur model la sisteme cu mai multe modele care utilizează punctele forte unice ale fiecărui model pentru sarcini specifice (de exemplu, generarea de cod, sumarizarea textului sau editarea imaginilor).
Rutare LLM a apărut ca o tehnică cheie pentru construirea și implementarea acestor sisteme, acționând ca un controlor de trafic care direcționează fiecare interogare a utilizatorului către modelul cel mai potrivit.
Metodele de rutare existente se împart în general în două categorii: „rutare bazată pe sarcini”, unde interogările sunt rutate pe baza unor sarcini predefinite, și „rutare bazată pe performanță”, care caută un echilibru optim între cost și performanță.
Cu toate acestea, rutarea bazată pe sarcini se confruntă cu intenții neclare sau schimbătoare ale utilizatorilor, în special în conversațiile cu mai multe rânduri de răspunsuri. Pe de altă parte, rutarea bazată pe performanță prioritizează rigid scorurile de referință, neglijează adesea preferințele utilizatorilor din lumea reală și se adaptează slab la noile modele, cu excepția cazului în care este supusă unor ajustări fine costisitoare.
Mai fundamental, așa cum notează cercetătorii de la Katanemo Labs în lucrarea lor hârtie„abordările de rutare existente au limitări în utilizarea în lumea reală. De obicei, acestea optimizează performanța de referință, neglijând în același timp preferințele umane determinate de criterii de evaluare subiective.”
Cercetătorii subliniază necesitatea unor sisteme de rutare care „se aliniază cu preferințele umane subiective, oferă mai multă transparență și rămân ușor adaptabile pe măsură ce modelele și cazurile de utilizare evoluează”.
Un nou cadru pentru rutare aliniată la preferințe
Pentru a aborda aceste limitări, cercetătorii propun un cadru de „rutare aliniată la preferințe” care potrivește interogările cu politicile de rutare pe baza preferințelor definite de utilizator.
În acest cadru, utilizatorii își definesc politicile de rutare în limbaj natural folosind o „Taxonomie Domeniu-Acțiune”. Aceasta este o ierarhie pe două niveluri care reflectă modul în care oamenii descriu în mod natural sarcinile, începând cu un subiect general (Domeniul, cum ar fi „juridic” sau „finanțe”) și restrângându-se la o sarcină specifică (Acțiunea, cum ar fi „rezumarea” sau „generarea de cod”).
Fiecare dintre aceste politici este apoi legată de un model preferat, permițând dezvoltatorilor să ia decizii de rutare bazate pe nevoile lumii reale, mai degrabă decât doar pe scorurile de referință. După cum se precizează în lucrare, „Această taxonomie servește drept model mental pentru a ajuta utilizatorii să definească politici de rutare clare și structurate.”
Procesul de rutare se desfășoară în două etape. În primul rând, un model de router aliniat la preferințe preia interogarea utilizatorului și setul complet de politici și selectează politica cea mai potrivită. În al doilea rând, o funcție de mapare conectează politica selectată la LLM-ul său desemnat.
Deoarece logica de selecție a modelului este separată de politică, modelele pot fi adăugate, eliminate sau schimbate pur și simplu prin editarea politicilor de rutare, fără a fi nevoie de reantrenarea sau modificarea routerului în sine. Această decuplare oferă flexibilitatea necesară pentru implementările practice, unde modelele și cazurile de utilizare sunt în continuă evoluție.
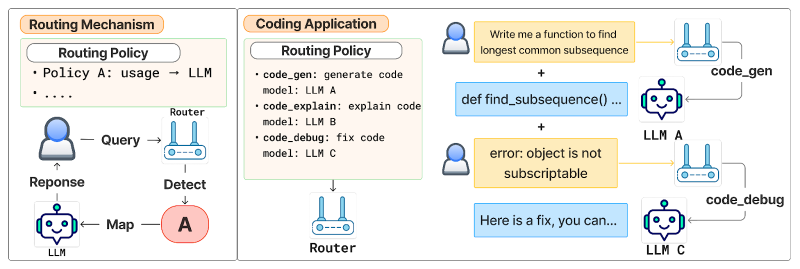
Selecția politicilor este susținută de Arch-Router, un model de limbaj compact de 1,5 B parametri, optimizat pentru rutare aliniată la preferințe. Arch-Router primește interogarea utilizatorului și setul complet de descrieri ale politicilor în promptul său. Apoi generează identificatorul politicii celei mai potrivite.
Întrucât politicile fac parte din datele de intrare, sistemul se poate adapta la rute noi sau modificate în momentul inferenței prin învățare în context și fără reantrenare. Această abordare generativă permite Arch-Router să își utilizeze cunoștințele pre-antrenate pentru a înțelege semantica atât a interogării, cât și a politicilor și să proceseze întregul istoric al conversațiilor simultan.
O preocupare frecventă legată de includerea unor politici extinse într-un prompt este potențialul de creștere a latenței. Cu toate acestea, cercetătorii au conceput Arch-Router pentru a fi extrem de eficient. „Deși lungimea politicilor de rutare poate deveni mare, putem crește cu ușurință fereastra de context a Arch-Router cu un impact minim asupra latenței”, explică Salman Paracha, coautor al lucrării și fondator/CEO al Katanemo Labs. El observă că latența este determinată în principal de lungimea rezultatului, iar pentru Arch-Router, rezultatul este pur și simplu numele scurt al unei politici de rutare, cum ar fi „editare_imagine” sau „creare_document”.
Arch-Router în acțiune
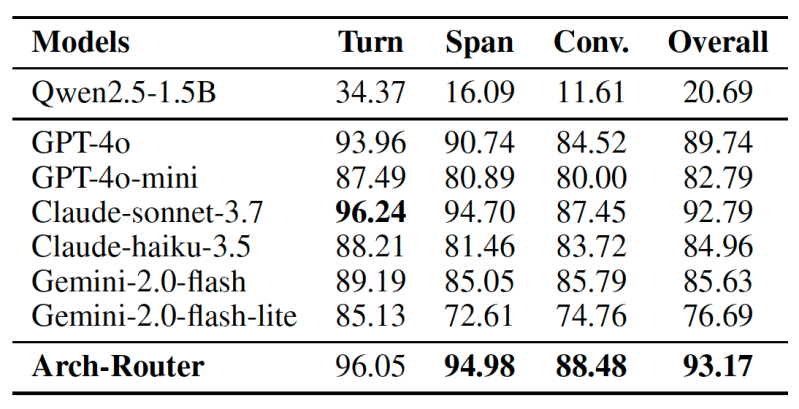
Pentru a construi Arch-Router, cercetătorii au ajustat fin o versiune cu parametri de 1,5 miliarde a Modelul Qwen 2.5 pe un set de date atent selecționat, format din 43.000 de exemple. Apoi, au testat performanța sa în raport cu modele proprietare de ultimă generație de la OpenAI, Anthropic și Google, pe patru seturi de date publice concepute pentru a evalua sistemele de inteligență artificială conversațională.
Rezultatele arată că Arch-Router obține cel mai mare scor general de rutare, de 93.17%, depășind toate celelalte modele, inclusiv cele proprietare de top, cu o medie de 7.71%. Avantajul modelului a crescut odată cu conversațiile mai lungi, demonstrând capacitatea sa puternică de a urmări contextul pe parcursul mai multor runde.
În practică, această abordare este deja aplicată în mai multe scenarii, potrivit lui Paracha. De exemplu, în instrumentele de codare open-source, dezvoltatorii folosesc Arch-Router pentru a direcționa diferite etape ale fluxului lor de lucru, cum ar fi „proiectarea codului”, „înțelegerea codului” și „generarea de cod”, către LLM-urile cele mai potrivite pentru fiecare sarcină. În mod similar, întreprinderile pot direcționa cererile de creare a documentelor către un model precum Sonetul lui Claude 3.7 în timp ce trimiteți sarcini de editare a imaginilor către Gemeni 2.5 Pro.
Sistemul este ideal și „pentru asistenții personali din diverse domenii, unde utilizatorii au o diversitate de sarcini, de la rezumatul textului la interogări de informații concrete”, a spus Paracha, adăugând că „în aceste cazuri, Arch-Router poate ajuta dezvoltatorii să unifice și să îmbunătățească experiența generală a utilizatorului”.
Acest cadru este integrat cu Arc, serverul proxy nativ bazat pe inteligență artificială de la Katanemo Labs pentru agenți, care permite dezvoltatorilor să implementeze reguli sofisticate de modelare a traficului. De exemplu, atunci când integrează un nou LLM, o echipă poate trimite o mică parte din trafic pentru o anumită politică de rutare către noul model, poate verifica performanța acestuia cu metrici interne și apoi poate tranziționa complet traficul cu încredere. Compania lucrează, de asemenea, la integrarea instrumentelor sale cu platforme de evaluare pentru a simplifica și mai mult acest proces pentru dezvoltatorii din mediul de afaceri.
În cele din urmă, obiectivul este de a depăși implementările izolate ale inteligenței artificiale. „Arch-Router – și Arch în sens larg – ajută dezvoltatorii și întreprinderile să treacă de la implementări LLM fragmentate la un sistem unificat, bazat pe politici”, spune Paracha. „În scenariile în care sarcinile utilizatorilor sunt diverse, framework-ul nostru ajută la transformarea fragmentării respectivei sarcini și a LLM într-o experiență unificată, făcând ca produsul final să fie perfect pentru utilizatorul final.”
