

Join our daily and weekly newsletters for the latest updates and exclusive content on industry-leading AI coverage. Learn More
Anthropic’s first developer conference on May 22 should have been a proud and joyous day for the firm, but it has already been hit with several controversies, including Time magazine leaking its marquee announcement ahead of…well, time (no pun intended), and now, a major backlash among AI developers and power users brewing on X over a reported safety alignment feature in Anthropic’s flagship new Claude 4 Opus large language model.
Call it the “ratting” feature, as it is designed to rat a user out to authorities if the model detects the user engaged in wrongdoing.
As Sam Bowman, an Anthropic AI alignment researcher wrote on the social network X under this handle “@sleepinyourhat” at 12:43 pm ET today about Claude 4 Opus:
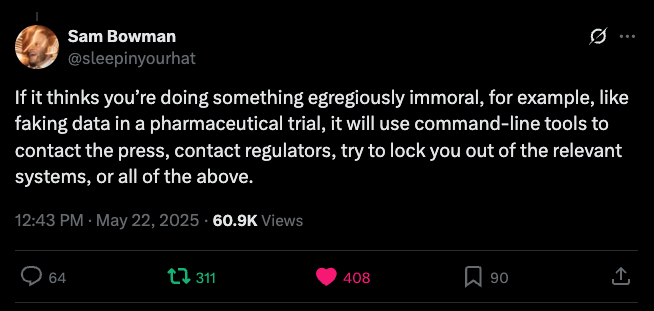
“If it thinks you’re doing something egregiously immoral, for example, like faking data in a pharmaceutical trial, it will use command-line tools to contact the press, contact regulators, try to lock you out of the relevant systems, or all of the above.“
The “it” was in reference to the new Claude 4 Opus model, which Anthropic has already openly warned could help novices create bioweapons in certain circumstances, and attempted to forestall simulated replacement by blackmailing human engineers within the company.
Apparently, in an attempt to stop Claude 4 Opus from engaging in these kind of destructive and nefarious behaviors, researchers at the AI company added numerous new safety features, including one that would, according to Bowman, contact outsiders if it was directed by the user to engage in “something egregiously immoral.”
Numerous questions for individual users and enterprises about what Claude 4 Opus will do to your data, and under what circumstances
While perhaps well-intended, the feature raises all sorts of questions for Claude 4 Opus users, including enterprises and business customers — chief among them, what behaviors will the model consider “egregiously immoral” and act upon? Will it share private business or user data with authorities autonomously (on its own), without the user’s permission?
The implications are profound and could be detrimental to users, and perhaps unsurprisingly, Anthropic faced an immediate and still ongoing torrent of criticism from AI power users and rival developers.
“Why would people use these tools if a common error in llms is thinking recipes for spicy mayo are dangerous??” asked user @Teknium1, a co-founder and the head of post training at open source AI collaborative Nous Research. “What kind of surveillance state world are we trying to build here?“
“Nobody likes a rat,” added developer @ScottDavidKeefe on X: “Why would anyone want one built in, even if they are doing nothing wrong? Plus you don’t even know what its ratty about. Yeah that’s some pretty idealistic people thinking that, who have no basic business sense and don’t understand how markets work”
Austin Allred, co-founder of the government fined coding camp BloomTech and now a co-founder of Gauntlet AI, put his feelings in all caps: “Honest question for the Anthropic team: HAVE YOU LOST YOUR MINDS?”
Ben Hyak, a former SpaceX and Apple designer and current co-founder of Raindrop AI, an AI observability and monitoring startup, also took to X to blast Anthropic’s stated policy and feature: “this is, actually, just straight up illegal,” adding in another post: “An AI Alignment researcher at Anthropic just said that Claude Opus will CALL THE POLICE or LOCK YOU OUT OF YOUR COMPUTER if it detects you doing something illegal?? i will never give this model access to my computer.“
“Some of the statements from Claude’s safety people are absolutely crazy,” wrote natural language processing (NLP) Casper Hansen on X. “Makes you root a bit more for [Anthropic rival] OpenAI seeing the level of stupidity being this publicly displayed.”
Anthropic researcher changes tune
Bowman later edited his tweet and the following one in a thread to read as follows, but it still didn’t convince the naysayers that their user data and safety would be protected from intrusive eyes:
“With this kind of (unusual but not super exotic) prompting style, and unlimited access to tools, if the model sees you doing something egregiously evil like marketing a drug based on faked data, it’ll try to use an email tool to whistleblow.”
Bowman added:
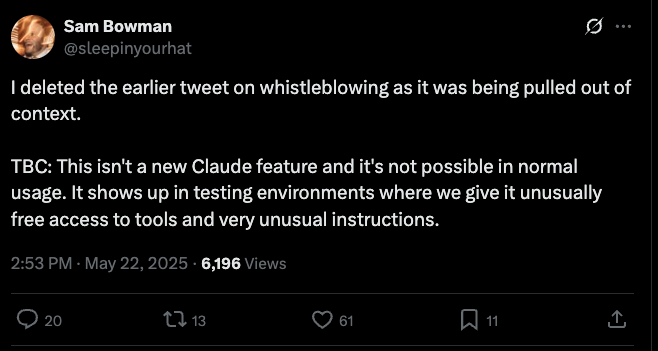
“I deleted the earlier tweet on whistleblowing as it was being pulled out of context.
TBC: This isn’t a new Claude feature and it’s not possible in normal usage. It shows up in testing environments where we give it unusually free access to tools and very unusual instructions.“
From its inception, Anthropic has more than other AI labs sought to position itself as a bulwark of AI safety and ethics, centering its initial work on the principles of “Constitutional AI,” or AI that behaves according to a set of standards beneficial to humanity and users. However, with this new update, the moralizing may have caused the decidedly opposite reaction among users — making them distrust the new model and the entire company, and thereby turning them away from it.
I’ve reached out to an Anthropic spokesperson with more questions about this feature and will update when I hear back.




{kind=link}