

Join the event trusted by enterprise leaders for nearly two decades. VB Transform brings together the people building real enterprise AI strategy. Learn more
A new framework from researchers at the University of Illinois, Urbana-Champaign, and the University of California, Berkeley gives developers more control over how large language models (LLMs) “think,” improving their reasoning capabilities while making more efficient use of their inference budget.
The framework, called AlphaOne (α1), is a test-time scaling technique, tweaking a model’s behavior during inference without needing costly retraining. It provides a universal method for modulating the reasoning process of advanced LLMs, offering developers the flexibility to improve performance on complex tasks in a more controlled and cost-effective manner than existing approaches.
The challenge of slow thinking
In recent years, developers of large reasoning models (LRMs), such as OpenAI o3 and DeepSeek-R1, have incorporated mechanisms inspired by “System 2” thinking—the slow, deliberate, and logical mode of human cognition. This is distinct from “System 1” thinking, which is fast, intuitive, and automatic. Incorporating System 2 capabilities enables models to solve complex problems in domains like mathematics, coding, and data analysis.
Models are trained to automatically generate transition tokens like “wait,” “hmm,” or “alternatively” to trigger slow thinking. When one of these tokens appears, the model pauses to self-reflect on its previous steps and correct its course, much like a person pausing to rethink a difficult problem.
However, reasoning models don’t always effectively use their slow-thinking capabilities. Different studies show they are prone to either “overthinking” simple problems, wasting computational resources, or “underthinking” complex ones, leading to incorrect answers.
As the AlphaOne paper notes, “This is because of the inability of LRMs to find the optimal human-like system-1-to-2 reasoning transitioning and limited reasoning capabilities, leading to unsatisfactory reasoning performance.”
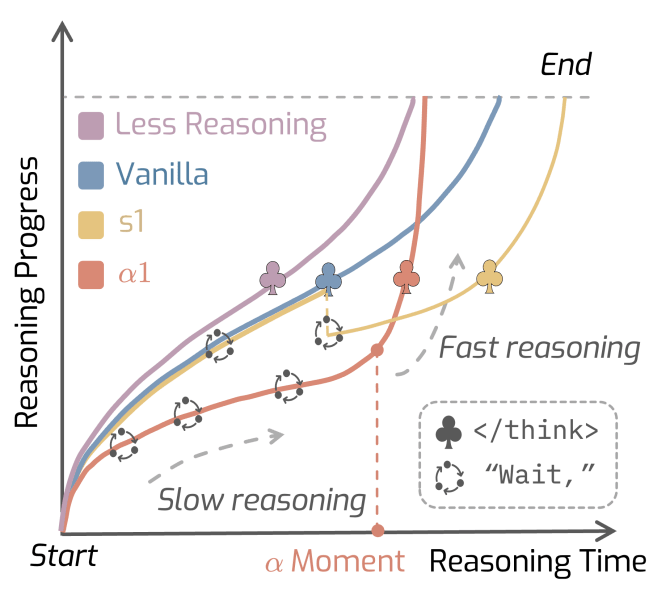
There are two common methods to address this. Parallel scaling, like the “best-of-N” approach, runs a model multiple times and picks the best answer, which is computationally expensive. Sequential scaling attempts to modulate the thinking process during a single run. For example, s1 is a technique that forces more slow thinking by adding “wait” tokens in the model’s context, while the “Chain of Draft” (CoD) method prompts the model to use fewer words, thereby reducing its thinking budget. These methods, however, offer rigid, one-size-fits-all solutions that are often inefficient.
A universal framework for reasoning
Instead of simply increasing or reducing the thinking budget, the researchers behind AlphaOne asked a more fundamental question: Is it possible to develop a better strategy for transitioning between slow and fast thinking that can modulate reasoning budgets universally?
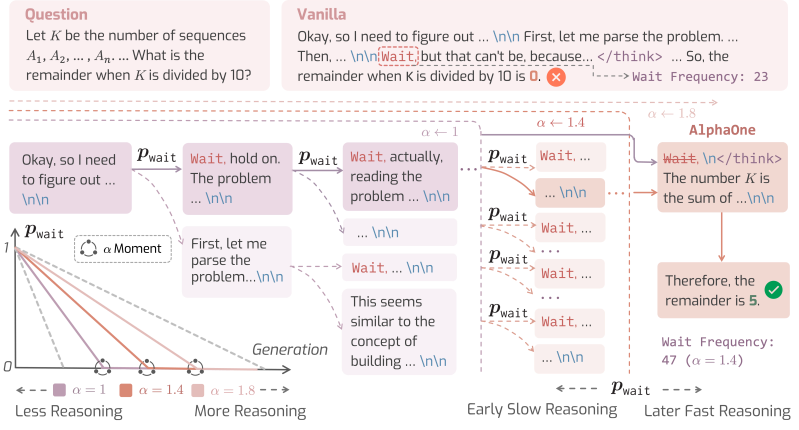
Their framework, AlphaOne, gives developers fine-grained control over the model’s reasoning process at test time. The system works by introducing Alpha (α), a parameter that acts as a dial to scale the model’s thinking phase budget.
Before a certain point in the generation, which the researchers call the “α moment,” AlphaOne strategically schedules how frequently it inserts a “wait” token to encourage slow, deliberate thought. This allows for what the paper describes as “both controllable and scalable thinking.”
Once the “α moment” is reached, the framework inserts a token in the mode’s context, ending the slow thinking process and forcing the model to switch to fast reasoning and produce its final answer.
Previous techniques typically apply what the researchers call “sparse modulation,” making only a few, isolated adjustments, such as adding a “wait” token once or twice during the entire process. AlphaOne, in contrast, can be configured to intervene often (dense) or rarely (sparse), giving developers more granular control than other methods.
“We see AlphaOne as a unified interface for deliberate reasoning, complementary to chain-of-thought prompting or preference-based tuning, and capable of evolving alongside model architectures,” the AlphaOne team told VentureBeat in written comments. “The key takeaway is not tied to implementation details, but to the general principle: slow-to-fast structured modulation of the reasoning process enhances capability and efficiency.”
AlphaOne in action
The researchers tested AlphaOne on three different reasoning models, with parameter sizes ranging from 1.5 billion to 32 billion. They evaluated its performance across six challenging benchmarks in mathematics, code generation, and scientific problem-solving.
They compared AlphaOne against three baselines: the vanilla, unmodified model; the s1 method that monotonically increases slow thinking; and the Chain of Draft (CoD) method that monotonically decreases it.
The results produced several key findings that are particularly relevant for developers building AI applications.
First, a “slow thinking first, then fast thinking” strategy leads to better reasoning performance in LRMs. This highlights a fundamental gap between LLMs and human cognition, which is usually structured based on fast thinking followed by slow thinking. Unlike humans, researchers found that models benefit from enforced slow thinking before acting fast.
“This suggests that effective AI reasoning emerges not from mimicking human experts, but from explicitly modulating reasoning dynamics, which aligns with practices such as prompt engineering and staged inference already used in real-world applications,” the AlphaOne team said. “For developers, this means that system design should actively impose a slow-to-fast reasoning schedule to improve performance and reliability, at least for now, while model reasoning remains imperfect.”
Another interesting finding was that investing in slow thinking can lead to more efficient inference overall. “While slow thinking slows down reasoning, the overall token length is significantly reduced with α1, inducing more informative reasoning progress brought by slow thinking,” the paper states. This means that although the model takes more time to “think,” it produces a more concise and accurate reasoning path, ultimately reducing the total number of tokens generated and lowering inference costs.
Compared to s1-style baselines, AlphaOne reduces average token usage by ~21%, resulting in lower compute overhead, while concurrently boosting reasoning accuracy by 6.15%, even on PhD-level math, science, and code problems.
“For enterprise applications like complex query answering or code generation, these gains translate into a dual benefit: improved generation quality and significant cost savings,” AlphaOne said. “These can lead to lower inference costs while improving task success rates and user satisfaction.”
Finally, the study found that inserting “wait” tokens with high frequency is helpful, with AlphaOne achieving better results by appending the token significantly more often than previous methods.
By giving developers a new level of control, the AlphaOne framework, whose code is expected to be released soon, could help them build more stable, reliable, and efficient applications on top of the next generation of reasoning models.
“For companies using open-source or custom-built models, especially those trained with transitioning tokens during the pre-training phase, AlphaOne is designed to be easy to integrate,” the AlphaOne team told VentureBeat. “In practice, integration typically requires minimal changes, such as simply updating the model name in the configuration scripts.”


{kind=link}