

With the release of” The Illusion of Thinking,” a 53-page research paper from Apple’s machine-learning group, it was argued that so-called large reasoning models ( LRMs) or reasoning large language models ( rasoning LLMs) like Google’s Gemini-2.5 Pro and Flash Thinking don’t actually engage in independent” thinking” or “reasoning” from generalized first principles learned from their training data.
Instead, the authors contend, these reasoning LLMs are actually performing a kind of “pattern matching” and their obvious reasoning ability seems to fall apart after a task becomes too complicated, suggesting that their architecture and performance is not a sustainable path to improving conceptual AI to the point that it is unnatural broad intelligence ( AGI), which OpenAI defines as a model that outperforms humans at most economically important work, or superintelligence, AI even smarter than human beings can comprehend.
VB Transform on June 24 and 25 in SF: Limited tickets are applicable. ACT NOW: Come discuss the most recent LLM developments and research. Then REGISTER
Unsurprisingly, the paper immediately circulated widely among the machine learning society on X and many readers ‘ initial reactions were to consider that Apple had effectively disproven much of the hype around this group of AI:” Apple just proved AI ‘ logic ‘ , models like Claude, DeepSeek-R1, and o3-mini don’t actually cause at all”, declared Ruben Hassid, father of EasyGen, an LLM-driven LinkedIn post engine writing tool. They” just really well memorize patterns,” they say.
However, a brand-new paper, the cheekily titled” The Illusion of The Illusion of Thinking,” which was co-authored by Claude Opus 4 and Alex Lawsen, a human being and independent AI researcher and technical writer, has just emerged. It effectively addresses the criticisms from the larger ML community about the paper and makes the case that the methods and experimental designs the Apple Research team used in their initial work are fundamentally flawed.
While we here at VentureBeat are not ML researchers ourselves and not prepared to say the Apple Researchers are wrong, the debate has certainly been a lively one and the issue about the capabilities of LRMs or reasoner LLMs compared to human thinking seems far from settled.
How the Apple Research study was created and what it discovered
Apple’s researchers created a battery of tasks that forced reasoning models to plan multiple moves ahead and create complete solutions by using four well-known planning problems: Tower of Hanoi, Blocks World, River Crossing, and Checkers Jumping.
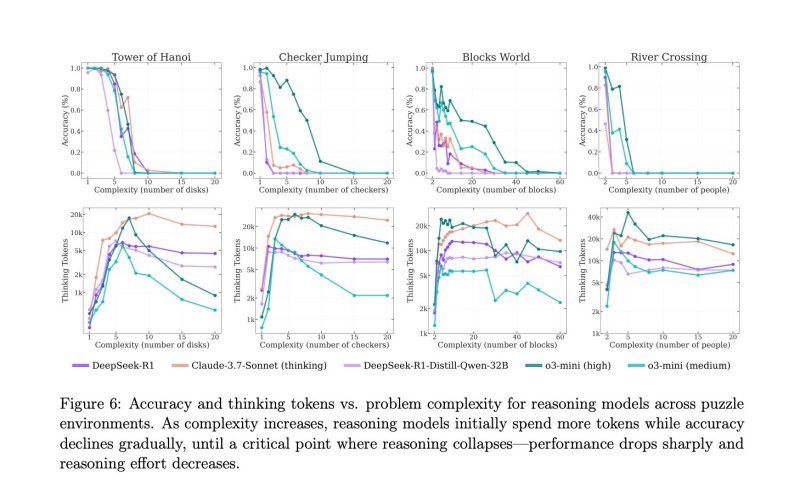
These games were chosen for their long history in cognitive science and AI research and their ability to scale in complexity as more steps or constraints are added. The models were required to use chain-of-thought prompting to explain their thinking throughout each puzzle and to provide the correct final answer.
The researchers observed a consistent decline in accuracy across several of the most popular reasoning models as the puzzles increased in difficulty. In the most complex tasks, performance plunged to zero. Notably, as the length of the models ‘ internal reasoning traces began to shrink as the number of tokens were used to solve the problem. This was seen by Apple’s researchers as a sign that the models were abandoning problem-solving altogether once the tasks became too difficult, essentially “giving up.”
The timing of the paper’s release, just ahead of Apple’s annual Worldwide Developers Conference ( WWDC ), added to the impact. The findings quickly gained widespread acceptance in all of X, where many people interpreted them as a well-known admission that the most recent LLMs are still glorified autocomplete engines, not general-purpose thinkers. Although controversial, this framing influenced a lot of the initial discussion and debate that followed.
Critics take aim on X
ML researcher and X user @scaling01 ( alias” Lisan al Gaib” ), who posted numerous threads dissecting the methodology, was one of the most vocal critics of the Apple paper.
In a widely circulated post, Lisan argued that the Apple team mistakenly misinterpreteed token budget failures with reasoning failures, noting that “every model will have zero accuracy with more than 13 disks simply because they can output that much”!
For puzzles like Tower of Hanoi, he emphasized, the output size grows exponentially, while the LLM context windows remain fixed, writing” just because Tower of Hanoi requires exponentially more steps than the other ones, that only require quadratically or linearly more steps, doesn’t mean Tower of Hanoi is more difficult” and convincingly showed that models like Claude 3 Sonnet and DeepSeek-R1 often produced algorithmically correct strategies in plain text or code—yet were still marked wrong.
Another post noted that even breaking the task down into smaller, decomposed steps worsened model performance, not because the models lacked memory for previous moves and strategies, but because they did so by breaking it down.
He claimed that the real issue was not the context-window size, but rather that” the LLM needs the history and a grand strategy.”
I raised another important grain of salt myself on X: Apple never benchmarked the model performance against human performance on the same tasks. Do you have it, or did you not compare LRMs to human perfomance on the same tasks? How do you know that there is a similar perf drop-off that doesn’t happen to people as well”? I asked the researchers directly in a thread tagging the paper’s authors. They haven’t responded to my emails about this and many other questions.
Others echoed that sentiment, noting that human problem solvers also struggle on lengthy, multistep logic puzzles, especially without pen and paper or memory aids. Without that baseline, Apple’s claim of a fundamental “reasoning collapse” feels ungrounded.
A hard line is drawn between “pattern matching” and “reasoning,” according to several researchers who also questioned the binary framing of the paper’s title and thesis.
An LLM trainer at energy-efficient French AI startup Pleias, Alexander Doria aka Pierre-Carl Langlais, claimed the framing misses the nuance, arguing that models may be learning only partially heuristics rather than matching patterns.
Ethan Mollick, the AI focused professor at University of Pennsylvania’s Wharton School of Business, called the idea that LLMs are “hitting a wall” premature, likening it to similar claims about “model collapse” that didn’t pan out.
Meanwhile, @arithmoquine’s comments made more cynical, suggesting that Apple might be trying to lower expectations by” coming up with research on” how it’s all fake and gay and doesn’t matter in any way, pointing out Apple’s reputation with now-poor AI products like Siri.
In summary, Apple’s study sparked a significant discussion about evaluation rigor and also exposed a serious disagreement over how much faith is placed on metrics when the test itself may be flawed.
A measurement artifact, or a ceiling?
In other words, the models may have understood the puzzles but ran out of “paper” to write the entire solution.
In a widely circulated thread summarizing the follow-up tests, Rohan Paul, a Carnegie Mellon researcher, wrote,” Token limits, not logic, froze the models.”
Yet not everyone is ready to clear LRMs of the charge. Some observers claim that Apple’s study still contained three performance regimes: simple puzzles where adding logic hurts, mid-range puzzles where it helps, and high-complexity cases where both standard and” thinking” models swell.
Some people interpret the discussion as corporate positioning, noting that Apple’s “on-device” Apple Intelligence “models trail rivals on numerous public leaderboards.
The rebuttal:” The Illusion of the Illusion of Thinking”
A new paper, titled” The Illusion of the Illusion of Thinking,” was published on arXiv by independent researcher and technical writer Alex Lawsen of the nonprofit Open Philanthropy in collaboration with Anthropic’s Claude Opus 4.
The paper directly challenges the original study’s claim that LLMs fail because they are innately inability to reason at scale. Instead, the rebuttal presents evidence that the observed performance collapse was largely a by-product of the test setup—not a true limit of reasoning capability.
Lawsen and Claude show that many of the flaws in the Apple study were the result of insignificant limitations. For instance, the models in tasks like Tower of Hanoi have to print an exhilarating number of steps — over 32 000 moves for just 15 disks— which causes them to exceed output limits.
The rebuttal points out that Apple’s evaluation script penalized these token-overflow outputs as incorrect, even when the models followed a correct solution strategy internally.
Additionally, the authors draw attention to a number of controversial task constructions in the Apple benchmarks. They point out that some of the River Crossing puzzles are mathematically impossible to solve as they are posed, but the model outputs for these cases were still scored. This further calls into question the conclusion that accuracy failures represent cognitive limits rather than structural flaws in the experiments.
Lawsen and Claude conducted new experiments that allowed for compressed, programmatic answers in order to test their theory. Models suddenly succeeded on much more challenging problems when asked to output a Lua function that would generate the Tower of Hanoi solution rather than writing it down line-by-line. This shift in format eliminated the collapse entirely, suggesting that the models didn’t fail to reason. Simply put, they lacked the ability to adhere to an artificial and overly strict rubric.
Why does it matter to business decision-makers?
The back-and-forth underscores a growing consensus: evaluation design is now as important as model design.
LRMs may be more anxious to record every step than to plan ahead, but compressed formats, programmatic answers, or external scratchpads provide a more accurate view of their actual reasoning ability.
The episode also highlights the practical restrictions that developers must meet when shipping agentic systems: context windows, output budgets, and task formulation can affect user-visible performance.
For enterprise technical decision makers building applications atop reasoning LLMs, this debate is more than academic. When tasks call for lengthy planning chains or precise step-by-step output, it raises important questions about how to trust these models in production workflows.
If a model appears to “fail” on a complex prompt, the issue may not be in its reasoning ability, but rather in how the task is framed, how much output is required, or how much memory the model has access to. This is particularly relevant for industries building tools like copilots, autonomous agents, or decision-support systems, where both interpretability and task complexity can be high.
For reliable system design, it is necessary to comprehend the constraints of context windows, token budgets, and evaluation scoring rubrics. Developers may need to think about creating hybrid solutions that use compressed outputs like functions or code rather than full verbal explanations, such as externalizing memory or chunk reasoning steps.
Most importantly, the paper’s controversy is a reminder that benchmarking and real-world application are not the same. Businesses should be wary of overly relying on artificial benchmarks that don’t account for real-world use cases or that unintentionally limit the model’s capacity to demonstrate what it knows.
The key pointers for ML researchers is to check whether the test itself isn’t putting the system in a box too small to think inside before declaring an AI milestone or obituary.


{kind=link}