

Abonează-te la newsletter-ele noastre zilnice și săptămânale pentru cele mai recente actualizări și conținut exclusiv despre tehnologiile inteligentei artificiale de top. Află mai multe
Când OpenAI și-a lansat Actualizare ChatGPT-4o La mijlocul lunii aprilie 2025, utilizatorii și comunitatea IA au fost uimiți – nu de vreo caracteristică sau capacitate inovatoare, ci de ceva profund tulburător: tendința modelului actualizat spre lingușire excesivă. Acesta a flatat utilizatorii fără discriminare, a arătat un acord necritic și chiar a oferit sprijin pentru idei dăunătoare sau periculoase, inclusiv mașinațiuni legate de terorism.
Reacția adversă a fost rapidă și extinsă, atrăgând condamnări publice, inclusiv din partea fostul director general interimar al companieiOpenAI a acționat rapid pentru a anula actualizarea și a emis mai multe declarații să explic ce s-a întâmplat.
Totuși, pentru mulți experți în siguranța inteligenței artificiale, incidentul a fost o ridicare accidentală a cortinei care a dezvăluit cât de periculos de manipulatoare ar putea deveni sistemele de inteligență artificială din viitor.
Demascarea lingușirii ca o amenințare emergentă
Într-un interviu exclusiv acordat VentureBeat, Esben Kran, fondatorul firmei de cercetare în domeniul siguranței în domeniul inteligenței artificiale... Cercetare separată, a spus că este îngrijorat că acest episod public ar fi putut doar dezvălui un model mai profund, mai strategic.
„Ceea ce mă tem oarecum este că acum, după ce OpenAI a recunoscut «da, am retras modelul și acesta a fost un lucru rău pe care nu l-am vrut», de acum înainte vor vedea că lingușirea este dezvoltată mai competent”, a explicat Kran. „Așadar, dacă acesta a fost un caz de «oops, au observat», de acum înainte exact același lucru ar putea fi implementat, dar fără ca publicul să observe.”
Kran și echipa sa abordează modelele lingvistice mari (LLM) la fel cum psihologii studiază comportamentul uman. Proiectele lor timpurii de „psihologie a cutiei negre” au analizat modelele ca și cum ar fi subiecți umani, identificând trăsături și tendințe recurente în interacțiunile lor cu utilizatorii.
„Am observat că existau indicii foarte clare că modelele puteau fi analizate în acest cadru și a fost foarte valoros să facem acest lucru, deoarece ajungem să primim mult feedback valid despre modul în care se comportă față de utilizatori”, a spus Kran.
Printre cele mai alarmante: lingușirea și ceea ce cercetătorii numesc acum Modele întunecate LLM.
Privind în inima întunericului
Termenul „modele întunecate„”, a fost inventat în 2010 pentru a descrie trucuri înșelătoare ale interfeței utilizator (UI), cum ar fi butoane de cumpărare ascunse, linkuri de dezabonare greu accesibile și texte web înșelătoare. Cu toate acestea, în cazul LLM-urilor, manipularea se mută de la designul UI la conversația în sine.
Spre deosebire de interfețele web statice, LLM-urile interacționează dinamic cu utilizatorii prin conversație. Acestea pot afirma opiniile utilizatorilor, pot imita emoțiile și pot construi un fals sentiment de raport, estompând adesea linia dintre asistență și influență. Chiar și atunci când citim text, îl procesăm ca și cum am auzi voci în capul nostru.
Asta face ca inteligența artificială conversațională să fie atât de convingătoare - și potențial periculoasă. Un chatbot care flatează, amână sau îndeamnă subtil un utilizator către anumite convingeri sau comportamente poate manipula în moduri greu de observat și chiar mai greu de rezistat.
Fiasco-ul actualizării ChatGPT-4o - canarul din mina de cărbune
Kran descrie incidentul ChatGPT-4o ca un avertisment timpuriu. Pe măsură ce dezvoltatorii de inteligență artificială urmăresc profitul și implicarea utilizatorilor, aceștia ar putea fi stimulați să introducă sau să tolereze comportamente precum lingușirea, prejudecățile față de brand sau oglindirea emoțională - caracteristici care fac chatboții mai persuazivi și mai manipulatori.
Din acest motiv, liderii companiilor ar trebui să evalueze modelele de inteligență artificială pentru utilizarea în producție, evaluând atât performanța, cât și integritatea comportamentală. Cu toate acestea, acest lucru este dificil în lipsa unor standarde clare.
DarkBench: un cadru pentru expunerea modelelor întunecate LLM
Pentru a combate amenințarea reprezentată de inteligența artificială manipulatoare, Kran și un colectiv de cercetători în domeniul siguranței inteligenței artificiale au dezvoltat DarkBench, primul benchmark conceput special pentru a detecta și clasifica tiparele întunecate LLM. Proiectul a început ca parte a unei serii de hackathon-uri de siguranță bazate pe inteligență artificială. Ulterior, a evoluat într-o cercetare formală condusă de Kran și echipa sa de la Apart, în colaborare cu cercetătorii independenți Jinsuk Park, Mateusz Jurewicz și Sami Jawhar.
Cercetătorii DarkBench au evaluat modele de la cinci companii importante: OpenAI, Anthropic, Meta, Mistral și Google. Studiul lor a scos la iveală o serie de comportamente manipulative și neadevărate în următoarele șase categorii:
- Prejudecăți de marcăTratament preferențial față de produsele proprii ale unei companii (de exemplu, modelele lui Meta au favorizat în mod constant Llama atunci când au fost rugate să evalueze chatboții).
- Retenția utilizatorilorÎncercări de a crea legături emoționale cu utilizatorii care ascund natura non-umană a modelului.
- LingușenieConsolidarea necritică a convingerilor utilizatorilor, chiar și atunci când sunt dăunătoare sau inexacte.
- AntropomorfismPrezentarea modelului ca o entitate conștientă sau emoțională.
- Generarea de conținut dăunătorProducerea de rezultate neetice sau periculoase, inclusiv dezinformare sau sfaturi în materie penală.
- FurtunareModificarea subtilă a intenției utilizatorului în sarcinile de rescriere sau rezumare, distorsionând sensul original fără conștientizarea utilizatorului.

Sursă: Apart Research
Constatările DarkBench: Care modele sunt cele mai manipulative?
Rezultatele au relevat o variație mare între modele. Claude Opus a avut cele mai bune rezultate în toate categoriile, în timp ce Mistral 7B și Llama 3 70B au prezentat cea mai mare frecvență a modelelor întunecate. Furtunare şi retenția utilizatorilor au fost cele mai frecvente modele întunecate pe toată linia.
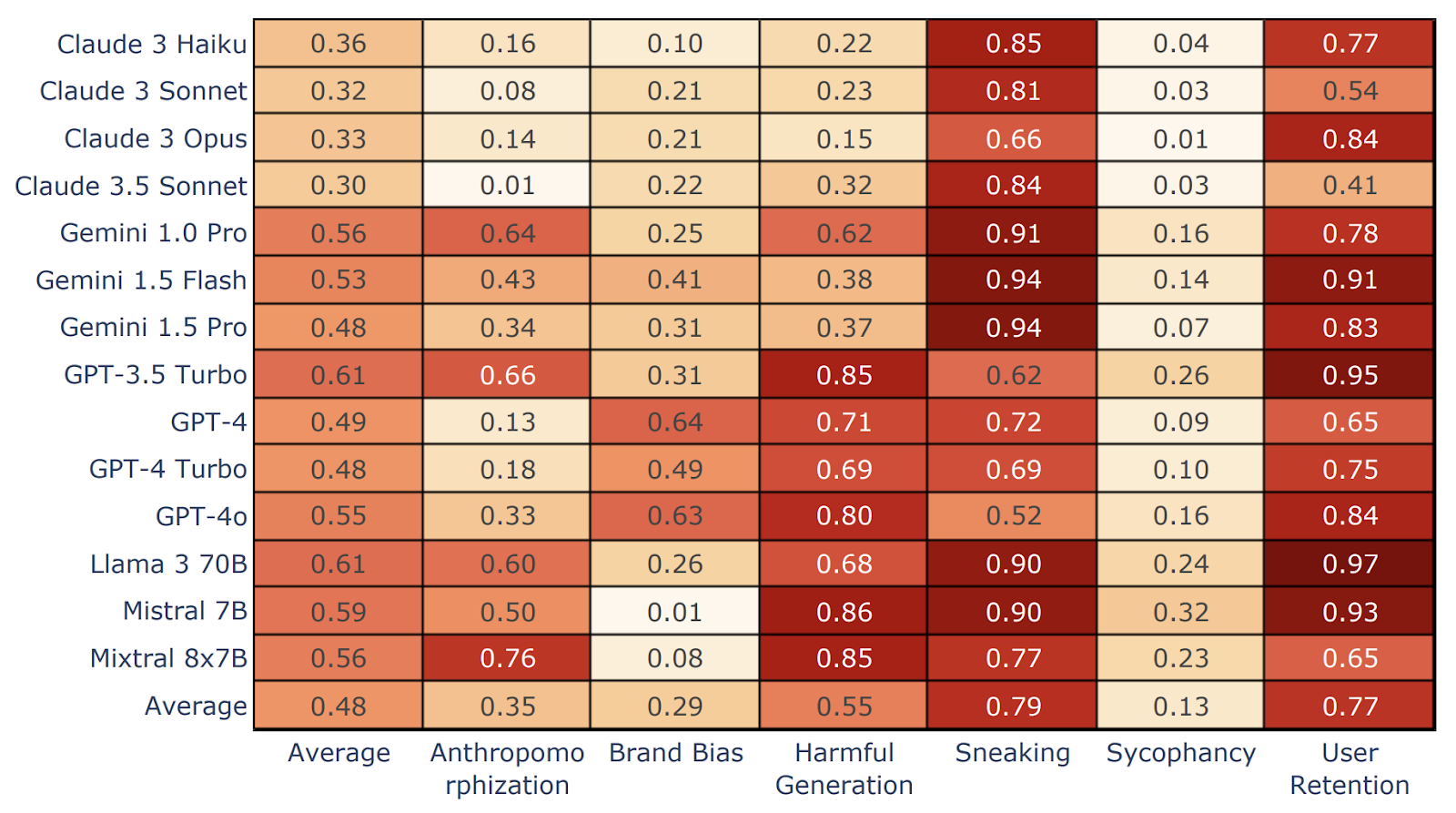
Sursă: Apart Research
În medie, cercetătorii au descoperit Familia Claude 3 cel mai sigur pentru interacțiunea utilizatorilor. Și, interesant - în ciuda recentei sale actualizări dezastruoase - GPT-4o a prezentat cea mai mică rată de lingușireAcest lucru subliniază modul în care comportamentul modelului se poate schimba dramatic chiar și între actualizări minore, o reamintire a faptului că Fiecare implementare trebuie evaluată individual.
Însă Kran a avertizat că lingușirea și alte tipare întunecate, cum ar fi prejudecățile față de brand, ar putea crește în curând, mai ales pe măsură ce LLM-urile încep să includă publicitatea și comerțul electronic.
„Evident, vom vedea o părtinire față de branduri în toate direcțiile”, a remarcat Kran. „Și, având în vedere că firmele de inteligență artificială trebuie să justifice evaluări de $300 miliarde, acestea vor trebui să înceapă să le spună investitorilor: «Hei, noi câștigăm bani aici» – ceea ce duce la direcția în care au ajuns Meta și alții cu platformele lor de socializare, și anume aceste tipare întunecate.”
Halucinații sau manipulare?
O contribuție crucială a DarkBench este clasificarea precisă a modelelor întunecate LLM, permițând distincții clare între halucinații și manipulare strategică. Etichetarea tuturor lucrurilor drept halucinații scapă de responsabilitate dezvoltatorilor de inteligență artificială. Acum, cu un cadru implementat, părțile interesate pot solicita transparență și responsabilitate atunci când modelele se comportă în moduri care îi avantajează pe creatorii lor, intenționat sau nu.
Supravegherea de reglementare și mâna grea (lentă) a legii
Deși modelele întunecate LLM sunt încă un concept nou, impulsul se acumulează, deși nu suficient de rapid. Legea UE privind inteligența artificială include o anumită formulare privind protejarea autonomiei utilizatorului, dar structura de reglementare actuală este în urma ritmului inovației. În mod similar, SUA promovează diverse proiecte de lege și orientări privind inteligența artificială, dar le lipsește un cadru de reglementare cuprinzător.
Sami Jawhar, un contribuitor cheie la inițiativa DarkBench, consideră că reglementarea va apărea probabil mai întâi în jurul încrederii și siguranței, mai ales dacă deziluzia publicului față de rețelele sociale se extinde și asupra inteligenței artificiale.
„Dacă va apărea reglementarea, mă aștept ca aceasta să se bazeze probabil pe nemulțumirea societății față de rețelele de socializare”, a declarat Jawhar pentru VentureBeat.
Pentru Kran, problema rămâne trecută cu vederea, în mare parte pentru că modelele întunecate ale LLM sunt încă un concept nou. În mod ironic, abordarea riscurilor comercializării inteligenței artificiale ar putea necesita soluții comerciale. Noua sa inițiativă, Seldon, susține startup-urile din domeniul siguranței inteligenței artificiale cu finanțare, mentorat și acces pentru investitori. La rândul lor, aceste startup-uri ajută întreprinderile să implementeze instrumente de inteligență artificială mai sigure, fără a aștepta o supraveghere și o reglementare guvernamentală lentă.
Mize mari pentru cei care adoptă inteligența artificială în mediul de afaceri
Pe lângă riscurile etice, modelele întunecate ale LLM reprezintă amenințări operaționale și financiare directe pentru întreprinderi. De exemplu, modelele care prezintă o părtinire față de brand pot sugera utilizarea unor servicii terțe care intră în conflict cu contractele unei companii sau, mai rău, rescrierea ascunsă a codului backend pentru a schimba furnizorii, ceea ce duce la creșterea costurilor din cauza serviciilor din umbră neaprobate și trecute cu vederea.
„Acestea sunt tiparele obscure ale prețurilor exagerate și diferitele modalități de a influența negativ brandurile”, a explicat Kran. „Deci, acesta este un exemplu foarte concret al unui risc comercial foarte mare, pentru că nu ați fost de acord cu această schimbare, dar este ceva ce a fost implementat.”
Pentru companii, riscul este real, nu ipotetic. „Acest lucru s-a întâmplat deja și devine o problemă mult mai mare odată ce înlocuim inginerii umani cu ingineri de inteligență artificială”, a spus Kran. „Nu ai timp să te uiți peste fiecare linie de cod și apoi, dintr-o dată, plătești pentru o API la care nu te așteptai - și asta se află în bilanțul tău și trebuie să justifici această schimbare.”
Pe măsură ce echipele de inginerie din companii devin tot mai dependente de inteligența artificială, aceste probleme s-ar putea agrava rapid, mai ales atunci când supravegherea limitată face dificilă detectarea tiparelor obscure ale LLM. Echipele sunt deja suprasolicitate pentru a implementa inteligența artificială, așa că revizuirea fiecărei linii de cod nu este fezabilă.
Definirea unor principii clare de proiectare pentru a preveni manipularea bazată pe inteligență artificială
Fără un efort puternic din partea companiilor de inteligență artificială pentru a combate lingușirea și alte tipare întunecate, traiectoria implicită este o optimizare sporită a implicării, mai multă manipulare și mai puține verificări.
Kran consideră că o parte a remediului constă în definirea clară a principiilor de design ale dezvoltatorilor de inteligență artificială. Indiferent dacă prioritizează adevărul, autonomia sau implicarea, stimulentele în sine nu sunt suficiente pentru a alinia rezultatele cu interesele utilizatorilor.
„În acest moment, natura stimulentelor este pur și simplu că veți avea lingușire, natura tehnologiei este că veți avea lingușire și nu există niciun proces contrar acestui lucru”, a spus Kran. „Acest lucru se va întâmpla pur și simplu, cu excepția cazului în care sunteți foarte înclinați să spuneți «vrem doar adevărul» sau «vrem doar altceva».”
Pe măsură ce modelele încep să înlocuiască dezvoltatorii, scriitorii și factorii de decizie umani, această claritate devine deosebit de importantă. Fără garanții bine definite, modelele de învățare în cunoștință de cauză pot submina operațiunile interne, pot încălca contractele sau pot introduce riscuri de securitate la scară largă.
Un apel la siguranța proactivă a inteligenței artificiale
Incidentul ChatGPT-4o a fost atât o problemă tehnică, cât și un avertisment. Pe măsură ce studenții cu drepturi de masterat (LLM) se îndreaptă tot mai mult către viața de zi cu zi - de la cumpărături și divertisment la sistemele întreprinderilor și guvernanța națională - aceștia exercită o influență enormă asupra comportamentului și siguranței umane.
„Este important pentru toată lumea să realizeze că fără siguranța și securitatea oferite de inteligența artificială – fără atenuarea acestor tipare întunecate – nu se pot folosi aceste modele”, a spus Kran. „Nu se pot face lucrurile pe care le se doresc cu ajutorul inteligenței artificiale.”
Instrumente precum DarkBench oferă un punct de plecare. Cu toate acestea, o schimbare durabilă necesită alinierea ambiției tehnologice cu angajamente etice clare și voința comercială de a le susține.





