

Doriți informații mai inteligente în căsuța dvs. poștală? Abonați-vă la newsletter-ele noastre săptămânale pentru a primi doar informații importante pentru liderii din domeniul inteligenței artificiale, datelor și securității în cadrul companiilor. Abonează-te acum
Cercetătorii de la Universitatea Illinois Urbana-Champaign și de la Universitatea Virginia au dezvoltat o nouă arhitectură de model care ar putea duce la sisteme de inteligență artificială mai robuste, cu capacități de raționament mai puternice.
Numit un transformator bazat pe energie (EBT), arhitectura demonstrează o capacitate naturală de a utiliza scalarea timpului de inferență pentru a rezolva probleme complexe. Pentru întreprinderi, acest lucru s-ar putea traduce în aplicații IA rentabile, care se pot generaliza la situații noi, fără a fi nevoie de modele specializate și reglate fin.
Provocarea gândirii Sistemului 2
În psihologie, gândirea umană este adesea împărțită în două moduri: Sistemul 1, care este rapid și intuitiv, și Sistemul 2, care este lent, deliberat și analitic. Modelele lingvistice mari (LLM) actuale excelează la sarcini de tip Sistem 1, dar industria inteligenței artificiale se concentrează din ce în ce mai mult pe permiterea gândirii Sistem 2 să abordeze provocări de raționament mai complexe.
Modelele de raționament utilizează diverse tehnici de scalare a timpului de inferență pentru a-și îmbunătăți performanța în rezolvarea problemelor dificile. O metodă populară este învățarea prin consolidare (RL), utilizată în modele precum DeepSeek-R1 și „OpenAI”seria O„modele”, în care inteligența artificială este recompensată pentru producerea de jetoane de raționament până când ajunge la răspunsul corect. O altă abordare, adesea numită „cel mai bun din n”, implică generarea mai multor răspunsuri potențiale și utilizarea unui mecanism de verificare pentru a-l selecta pe cel mai bun.
Totuși, aceste metode au dezavantaje semnificative. Adesea sunt limitate la o gamă restrânsă de probleme ușor verificabile, cum ar fi matematica și codarea, și pot degrada performanța în alte sarcini, cum ar fi scrierea creativă. În plus, dovezi recente sugerează că abordările bazate pe învățarea prin învățare (RL) ar putea să nu le predea modelelor noi abilități de raționament, ci doar să le facă mai predispuse să utilizeze cu succes modele de raționament pe care le cunosc deja. Acest lucru le limitează capacitatea de a rezolva probleme care necesită o explorare reală și care depășesc regimul lor de antrenament.
Modele bazate pe energie (EBM)
Arhitectura propune o abordare diferită, bazată pe o clasă de modele cunoscute sub numele de modele bazate pe energie (EBM). Ideea de bază este simplă: în loc să genereze direct un răspuns, modelul învață o „funcție energetică” care acționează ca un verificator. Această funcție preia o intrare (cum ar fi un prompt) și o predicție candidată și îi atribuie o valoare sau „energie”. Un scor energetic scăzut indică o compatibilitate ridicată, ceea ce înseamnă că predicția se potrivește bine cu intrarea, în timp ce un scor energetic ridicat semnifică o potrivire slabă.
Aplicând acest lucru la raționamentul bazat pe inteligență artificială, cercetătorii propun în o hârtie că dezvoltatorii ar trebui să considere „gândirea ca pe o procedură de optimizare în raport cu un verificator învățat, care evaluează compatibilitatea (probabilitatea nenormalizată) dintre o intrare și o predicție candidată”. Procesul începe cu o predicție aleatorie, care este apoi rafinată progresiv prin minimizarea scorului său energetic și explorarea spațiului de soluții posibile până când converge către un răspuns extrem de compatibil. Această abordare se bazează pe principiul că verificarea unei soluții este adesea mult mai ușoară decât generarea uneia de la zero.
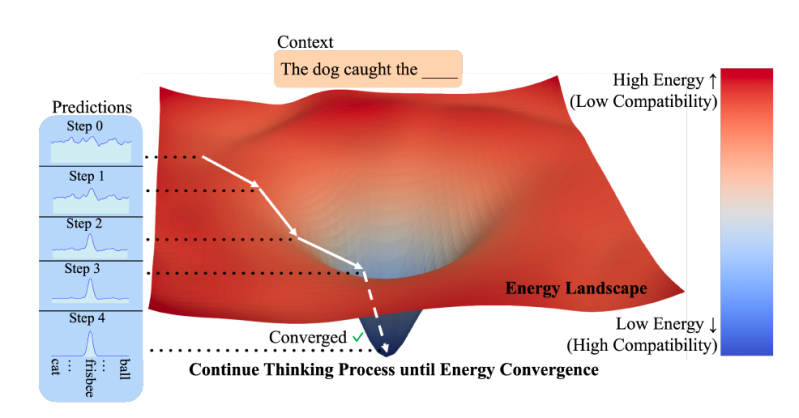
Acest design „centrat pe verificator” abordează trei provocări cheie în raționamentul bazat pe inteligență artificială. În primul rând, permite alocarea dinamică a calculelor, ceea ce înseamnă că modelele pot „gândi” mai mult timp la probleme mai dificile și mai puțin timp la probleme ușoare. În al doilea rând, modelele bazate pe informații financiare (EBM) pot gestiona în mod natural incertitudinea problemelor din lumea reală, unde nu există un răspuns clar. În al treilea rând, acestea acționează ca proprii verificatori, eliminând necesitatea unor modele externe.
Spre deosebire de alte sisteme care utilizează generatoare și verificatoare separate, EBM-urile combină ambele într-un singur model unificat. Un avantaj cheie al acestui aranjament este o generalizare mai bună. Deoarece verificarea unei soluții pe date noi, în afara distribuției (OOD), este adesea mai ușoară decât generarea unui răspuns corect, EBM-urile pot gestiona mai bine scenarii nefamiliare.
În ciuda promisiunilor lor, EBM-urile s-au confruntat dintotdeauna cu dificultăți în ceea ce privește scalabilitatea. Pentru a rezolva această problemă, cercetătorii introduc EBT-uri, care sunt soluții specializate modele de transformatoare conceput pentru această paradigmă. EBT-urile sunt antrenate să verifice mai întâi compatibilitatea dintre un context și o predicție, apoi să rafineze predicțiile până când găsesc rezultatul cu cea mai mică energie (cel mai compatibil). Acest proces simulează eficient un proces de gândire pentru fiecare predicție. Cercetătorii au dezvoltat două variante EBT: un model doar decodor inspirat de arhitectura GPT și un model bidirecțional similar cu BERT.
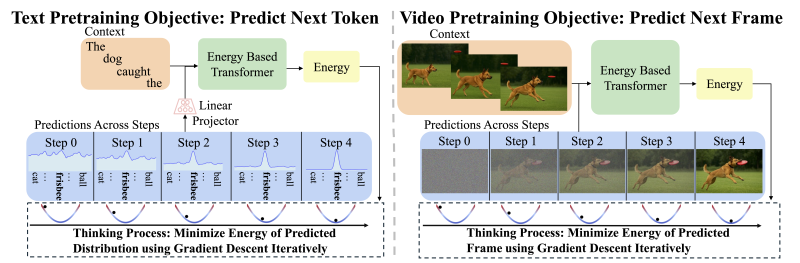
Arhitectura EBT-urilor le face flexibile și compatibile cu diverse tehnici de scalare a timpului de inferență. „EBT-urile pot genera CoT-uri mai lungi, se pot autoverifica, pot face best-of-N [sau] puteți preleva eșantioane din mai multe EBT-uri”, a declarat pentru VentureBeat Alexi Gladstone, doctorandă în informatică la Universitatea din Illinois, Urbana-Champaign, și autoarea principală a lucrării. „Cel mai bun lucru este că toate aceste capacități sunt învățate în timpul antrenamentelor prealabile.”
EBT-uri în acțiune
Cercetătorii au comparat EBT-urile cu arhitecturi consacrate: popularele transformator++ rețetă pentru generarea de text (modalități discrete) și transformatorul de difuzie (DiT) pentru sarcini precum predicția video și eliminarea zgomotului din imagini (modalități continue). Aceștia au evaluat modelele pe baza a două criterii principale: „scalabilitatea învățării” sau cât de eficient se antrenează și „scalabilitatea gândirii”, care măsoară modul în care performanța se îmbunătățește odată cu mai multe calcule la momentul inferenței.
În timpul antrenamentului prealabil, EBT-urile au demonstrat o eficiență superioară, atingând o rată de scalare cu până la 35% mai mare decât Transformer++ în ceea ce privește datele, dimensiunea lotului, parametrii și calculul. Aceasta înseamnă că EBT-urile pot fi antrenate mai rapid și mai ieftin.
La inferență, EBT-urile au depășit și modelele existente în sarcinile de raționament. Prin „gândirea mai lungă” (folosind mai mulți pași de optimizare) și efectuând „autoverificare” (generând mai mulți candidați și alegându-l pe cel cu cea mai mică energie), EBT-urile au îmbunătățit performanța modelării limbajului cu 29% mai mult decât Transformer++. „Acest lucru se aliniază cu afirmațiile noastre conform cărora, deoarece transformatoarele tradiționale feed-forward nu pot aloca dinamic calcule suplimentare pentru fiecare predicție făcută, acestea nu pot îmbunătăți performanța pentru fiecare token gândindu-se mai mult”, scriu cercetătorii.
Pentru eliminarea zgomotului din imagine, EBT-urile au obținut rezultate mai bune decât DiT-urile, utilizând cu 99% mai puține treceri înainte.
Un aspect crucial este că studiul a constatat că EBT-urile generalizează mai bine decât alte arhitecturi. Chiar și cu performanțe identice sau mai slabe înainte de antrenament, EBT-urile au depășit modelele existente în sarcinile din aval. Câștigurile de performanță obținute prin gândirea Sistemului 2 au fost cele mai substanțiale în cazul datelor care erau în afara distribuției (diferite de datele de antrenament), sugerând că EBT-urile sunt deosebit de robuste atunci când se confruntă cu sarcini noi și provocatoare.
Cercetătorii sugerează că „beneficiile gândirii bazate pe EBT-uri nu sunt uniforme în toate datele, ci se modifică pozitiv odată cu magnitudinea schimbărilor distribuționale, evidențiind gândirea ca mecanism critic pentru o generalizare robustă dincolo de distribuțiile de antrenament.”
Beneficiile EBT-urilor sunt importante din două motive. În primul rând, acestea sugerează că, la scara masivă a modelelor de fundație actuale, EBT-urile ar putea depăși semnificativ arhitectura clasică a transformatoarelor utilizată în LLM-uri. Autorii notează că „la scara modelelor de fundație moderne antrenate pe baza a de 1.000 de ori mai multe date, cu modele de 1.000 de ori mai mari, ne așteptăm ca performanța de pre-antrenament a EBT-urilor să fie semnificativ mai bună decât cea a rețetei Transformer++.”
În al doilea rând, EBT-urile demonstrează o eficiență mult mai bună a datelor. Acesta este un avantaj esențial într-o epocă în care datele de antrenament de înaltă calitate devin un blocaj major pentru scalarea inteligenței artificiale. „Deoarece datele au devenit unul dintre principalii factori limitatori în scalarea ulterioară, acest lucru face ca EBT-urile să fie deosebit de atractive”, conchide lucrarea.
În ciuda mecanismului său de inferență diferit, arhitectura EBT este extrem de compatibilă cu transformatorul, ceea ce face posibilă utilizarea acestora ca înlocuitor drop-in pentru LLM-urile actuale.
„EBT-urile sunt foarte compatibile cu hardware-ul/framework-urile de inferență actuale”, a spus Gladstone, inclusiv decodarea speculativă folosind modele feed-forward atât pe GPU-uri, cât și pe TPU-uri. El a spus că este, de asemenea, încrezător că pot rula pe acceleratoare specializate, cum ar fi LPU-urile și algoritmi de optimizare, cum ar fi FlashAttention-3sau pot fi implementate prin intermediul unor cadre de inferență comune, cum ar fi vLLM.
Pentru dezvoltatori și companii, capacitățile puternice de raționament și generalizare ale EBT-urilor le-ar putea transforma într-o bază puternică și fiabilă pentru construirea următoarei generații de aplicații de inteligență artificială. „Gândirea pe termen lung poate fi de ajutor în general pentru aproape toate aplicațiile companiilor, dar cred că cele mai interesante vor fi cele care necesită decizii mai importante, siguranță sau aplicații cu date limitate”, a spus Gladstone.


{kind=link}