

Abonează-te la newsletter-ele noastre zilnice și săptămânale pentru cele mai recente actualizări și conținut exclusiv despre tehnologiile inteligentei artificiale de top. Află mai multe
Universitatea din California, Santa Cruz, a anunțat lansarea OpenVision, o familie de codificatoare vizuale care își propun să ofere o nouă alternativă la modelele care includ CLIP-ul OpenAI, vechi de patru ani şi anul trecut SigLIP de la Google.
Un codificator vizual este un tip de model de inteligență artificială care transformă materiale vizuale și fișiere — de obicei imagini statice încărcate de creatorii unui model — în date numerice care pot fi înțelese de alte modele de inteligență artificială non-vizuale, cum ar fi modelele de limbaj larg (LLM). Un codificator vizual este o componentă necesară pentru a permite multor LLM de top să lucreze cu imagini încărcate de utilizatori, permițând unui LLM să identifice diferite subiecte de imagine, culori, locații și alte caracteristici dintr-o imagine.
OpenVision, așadar, cu licență Apache 2.0 permisivă și familia 26 (!) modele diferite Cuprinzând între 5,9 milioane de parametri și 632,1 milioane de parametri, permite oricărui dezvoltator sau creator de modele AI din cadrul unei întreprinderi sau organizații să preia și să implementeze un codificator care poate fi utilizat pentru a ingera totul, de la imagini de pe un șantier până la mașina de spălat a unui utilizator, permițând unui model AI să ofere îndrumări și depanare sau o multitudine de alte cazuri de utilizare. Licența Apache 2.0 permite utilizarea în aplicații comerciale.
Modelele au fost dezvoltate de o echipă condus de Cihang Xie, profesor asistent la UCSC, împreună cu colaboratorii Xianhang Li, Yanqing Liu, Haoqin Tu și Hongru Zhu.
Proiectul se bazează pe canalul de antrenament CLIPS și valorifică setul de date Recap-DataComp-1B, o versiune recapționată a unui corpus de imagini web la scară miliarde folosind modele lingvistice bazate pe LLaVA.
Arhitectură scalabilă pentru diferite cazuri de utilizare a implementării la nivel de întreprindere
Designul OpenVision acceptă mai multe cazuri de utilizare.
Modelele mai mari sunt potrivite pentru sarcini de lucru la nivel de server care necesită o precizie ridicată și o înțelegere vizuală detaliată, în timp ce variantele mai mici - unele cu parametri de doar 5,9 milioane - sunt optimizate pentru implementări edge unde capacitatea de calcul și memoria sunt limitate.
Modelele acceptă, de asemenea, dimensiuni adaptive ale patch-urilor (8×8 și 16×16), permițând compromisuri configurabile între rezoluția detaliilor și sarcina de calcul.
Rezultate puternice în cadrul parametrilor de referință multimodali
Într-o serie de teste de performanță, OpenVision demonstrează rezultate solide în mai multe sarcini legate de limbajul vizual.
Deși testele de referință CLIP tradiționale, cum ar fi ImageNet și MSCOCO, rămân parte a suitei de evaluare, echipa OpenVision avertizează împotriva bazării exclusive pe aceste valori.
Experimentele lor arată că performanțele puternice în clasificarea sau regăsirea imaginilor nu se traduc neapărat în succes în raționamentul multimodal complex. În schimb, echipa pledează pentru o acoperire mai largă a benchmark-urilor și protocoale de evaluare deschise care să reflecte mai bine cazurile de utilizare multimodală din lumea reală.
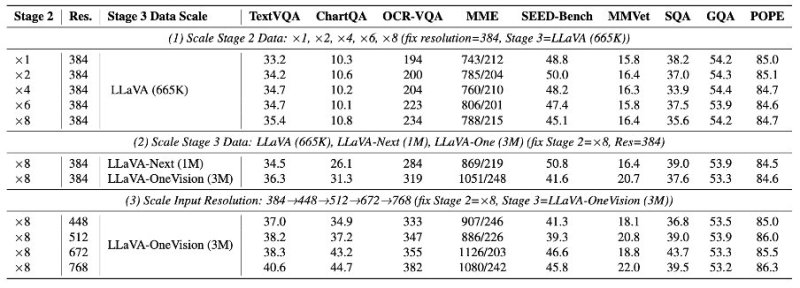
Evaluările au fost efectuate folosind două cadre multimodale standard — LLaVA-1.5 și Open-LLaVA-Next — și au arătat că modelele OpenVision se potrivesc în mod constant cu sau chiar depășesc atât CLIP, cât și SigLIP în sarcini precum TextVQA, ChartQA, MME și OCR.
În configurația LLaVA-1.5, codificatoarele OpenVision antrenate la o rezoluție de 224×224 au obținut scoruri mai mari decât CLIP-ul OpenAI atât în sarcinile de clasificare, cât și în cele de recuperare, precum și în evaluările ulterioare, cum ar fi SEED, SQA și POPE.
La rezoluții de intrare mai mari (336×336), OpenVision-L/14 a depășit performanța CLIP-L/14 în majoritatea categoriilor. Chiar și modelele mai mici, cum ar fi OpenVision-Small și Tiny, au menținut o precizie competitivă, utilizând în același timp semnificativ mai puțini parametri.
Antrenamentul progresiv eficient reduce costurile de calcul
O caracteristică notabilă a OpenVision este strategia sa de antrenament progresiv al rezoluției, adaptată de la CLIPA. Modelele încep antrenamentul pe imagini cu rezoluție mică și sunt ajustate treptat la rezoluții mai mari.
Acest lucru are ca rezultat un proces de antrenament mai eficient din punct de vedere al calculului - adesea de 2 până la 3 ori mai rapid decât CLIP și SigLIP - fără pierderi de performanță în downstream.
Studii de ablație — unde componentele unui model de învățare automată sunt eliminate selectiv pentru a identifica importanța sau lipsa acesteia pentru funcționarea sa — confirmă în continuare beneficiile acestei abordări, cele mai mari câștiguri de performanță observate în sarcini de înaltă rezoluție, sensibile la detalii, cum ar fi OCR și răspunsurile vizuale la întrebări bazate pe grafice.
Un alt factor în performanța OpenVision este utilizarea subtitrărilor sintetice și a unui decodor de text auxiliar în timpul antrenamentului.
Aceste alegeri de design permit codificatorului vizual să învețe reprezentări mai bogate semantic, îmbunătățind precizia în sarcinile de raționament multimodal. Eliminarea oricăreia dintre componente a dus la scăderi constante de performanță în testele de ablație.
Optimizat pentru sisteme ușoare și cazuri de utilizare edge computing
OpenVision este, de asemenea, conceput să funcționeze eficient cu modele lingvistice mici.
Într-un experiment, un codificator vizual a fost asociat cu un Smol-LM cu 150M parametri pentru a construi un model multimodal complet cu 250M parametri.
În ciuda dimensiunilor reduse, sistemul a menținut o precizie robustă într-o suită de sarcini de evaluare a calității vitezei (VQA), înțelegere a documentelor și raționament.
Această capacitate sugerează un potențial puternic pentru implementări bazate pe edge sau cu resurse limitate, cum ar fi smartphone-urile de larg consum sau camerele și senzorii de producție la fața locului.
De ce este important OpenVision pentru factorii de decizie tehnică din companii
Abordarea complet deschisă și modulară a OpenVision în ceea ce privește dezvoltarea de codificatoare vizuale are implicații strategice pentru echipele din companii care lucrează în inginerie de inteligență artificială, orchestrare, infrastructură de date și securitate.
Pentru inginerii care supraveghează dezvoltarea și implementarea LLM, OpenVision oferă o soluție plug-and-play pentru integrarea capabilităților de vizualizare de înaltă performanță, fără a depinde de API-uri opace, terțe sau de licențe de model restricționate.
Această deschidere permite o optimizare mai strictă a proceselor de vizualizare-limbaj și asigură că datele proprietare nu părăsesc niciodată mediul organizației.
Pentru inginerii axați pe crearea de cadre de orchestrare AI, OpenVision oferă modele la o gamă largă de scale de parametri - de la codificatoare ultracompacte potrivite pentru dispozitive edge până la modele mai mari, de înaltă rezoluție, potrivite pentru conducte cloud cu mai multe noduri.
Această flexibilitate facilitează proiectarea unor fluxuri de lucru MLOps scalabile și eficiente din punct de vedere al costurilor, fără a compromite precizia specifică sarcinii. Suportul său pentru antrenamentul de rezoluție progresivă permite, de asemenea, o alocare mai inteligentă a resurselor în timpul dezvoltării, ceea ce este benefic în special pentru echipele care operează cu constrângeri bugetare stricte.
Inginerii de date pot utiliza OpenVision pentru a alimenta canale analitice bazate pe imagini, unde datele structurate sunt completate cu intrări vizuale (de exemplu, documente, diagrame, imagini de produse). Deoarece grădina zoologică cu modele acceptă rezoluții de intrare multiple și dimensiuni de patch-uri, echipele pot experimenta compromisuri între fidelitate și performanță fără a fi nevoie să se antreneze din nou de la zero. Integrarea cu instrumente precum PyTorch și Hugging Face simplifică implementarea modelului în sistemele de date existente.
Între timp, arhitectura transparentă și canalul de antrenament reproductibil al OpenVision permit echipelor de securitate să evalueze și să monitorizeze modelele pentru potențiale vulnerabilități - spre deosebire de API-urile de tip „cutie neagră”, unde comportamentul intern este inaccesibil.
Atunci când sunt implementate local, aceste modele evită riscurile de scurgere a datelor în timpul inferenței, aspect esențial în industriile reglementate care gestionează date vizuale sensibile, cum ar fi actele de identitate, formularele medicale sau înregistrările financiare.
În toate aceste roluri, OpenVision ajută la reducerea dependenței de un furnizor și aduce beneficiile inteligenței artificiale multimodale moderne în fluxuri de lucru care necesită control, personalizare și transparență operațională. Oferă echipelor din companii baza tehnică pentru a construi aplicații competitive, îmbunătățite prin inteligență artificială - în propriile condiții.
Deschis pentru afaceri
Grădina zoologică a modelelor OpenVision este disponibilă atât în implementările PyTorch, cât și în cele JAX, iar echipa a lansat și utilitare pentru integrarea cu framework-uri populare de limbaje de vizualizare.
Începând cu această lansare, modelele pot fi descărcat de la Hugging Faceși rețetele de antrenament sunt postate public pentru reproductibilitate completă.
Prin furnizarea unei alternative transparente, eficiente și scalabile la codificatoarele proprietare, OpenVision oferă cercetătorilor și dezvoltatorilor o bază flexibilă pentru dezvoltarea aplicațiilor de limbaj vizual. Lansarea sa marchează un pas semnificativ înainte în promovarea unei infrastructuri multimodale deschise - în special pentru cei care doresc să construiască sisteme performante fără acces la date închise sau la conducte de antrenament cu resurse mari de calcul.
Pentru documentație completă, teste de performanță și descărcări, vizitați Pagina proiectului OpenVision sau Depozit GitHub.








{kind=link}